Abstract
The paper explores how LLMs perform when operating on raw HTML of a webpage. They are the first paper to explore LLMs performance on raw, unprocessed HTML.
They finetune models to operate on raw HTML and assess the models on three tasks:
- Semantic classification (ex. something is a submit button or email entry field).
- Description generation for HTML inputs (ex “please enter your email here”).
- Autonomous web navigation (clicking elements to achieve a task).
They found LLMs pretrained on a standard dataset (not HTML focused) transfer very well to HTML understanding tasks and can achieve better performance with less finetuning data (they completed 50% more tasks using 192x less data on MiniWOB benchmark).
They found the T5-based models perform best because of their bidirectional encoder-decoder architecture.
They created and open-sourced a large scale HTML dataset distilled and auto-labeled from CommonCrawl. This dataset is used for description generation training.
Introduction
They want to create an agent that can search for specific content or controls on a web page and navigate the site autonomously.
It is common in NLP to take a LLM pretrained on a large text corpus and then fine tune or prompt the LLM on a task-specific dataset. They want to apply the same strategy to understanding HTML.
Operating on HTML

In the example above, there are two <input> tags (one for email and one for password) and their corresponding labels are in a separate branch of the page.
Each element has a set of attributes that can be thought of as key-value pairs. These attributes decide what will be shown when the element is rendered. In the example above, the HTML element:
<input type="email" id="uName">has the attributes:
tag: "input"type: "email"id: "uName"
Pre-processing pipeline
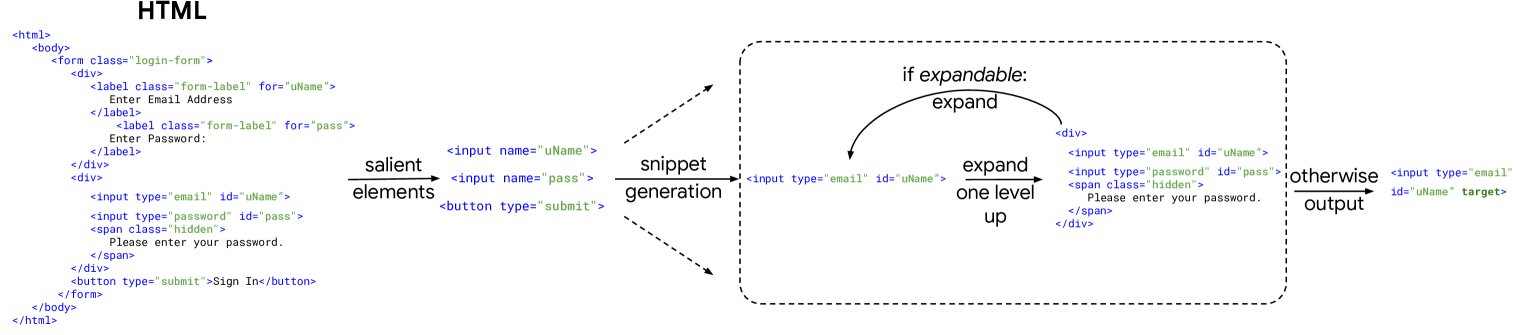 Given a web page they detect
Given a web page they detect
Tasks
They have three tasks that they use to benchmark the models understanding of HTML.
Semantic Classification
Classify a given HTML element as a specific category (ex. address, email, or password).
Description Generation:
The model is given an HTML snippet and prompted to produce a natural language description (ex. when given an email field the description generated could be “Please enter your email address”).
Autonomous Web Navigation
A model is given an HTML page and a natural language command and must apply appropriate actions on a sequence of HTML pages to satisfy the command.
Related Work
Most papers that work with LLMs and HTML usually fall into one of two groups:
- Preprocess HTML into natural language and then ask an LLM to assist with web navigation. Requiring preprocessing restricts which HTML pages the model can parse. (natural language input -> HTML action)
- Pretrain LLMs on raw HTML and then ask the LLM questions about it where the output is in natural language (ex. summarize or question/answering). (raw HTML input -> natural language output).
This paper is different in that it takes raw HTML input and then is able to take HTML actions.
Dataset
They use the MiniWOB dataset to assess how the model performs on web navigation. However, they also wanted to be able to assess the models on real-world websites so they created their own dataset for the description generation task based on CommonCrawl.
Ablation Studies
Removing closing HTML tags
They evaluated the models performance when they removed closing HTML tags but kept the order of elements the same.
Ex: converting
<div id="form"><div><input id="username"></div></div>
into
<div id="form"><div><input id="username">
The model saw a 6% decrease in success rate on MiniWoB which suggests that the model is partially dependent on the DOM topology.
Performance drop might be explained by other reasons.
They evaluated an already trained WebN-T5-3B model on the same synthetic websites with the structure corrupted and the performance dropped. The performance might not have dropped so much if they had trained the model on this format of data originally vs. using a model that was trained with the non-corrupted data. The T5 model is a bidirectional encoder so it makes sense that information to the left and right of the relevant element is used in the encoding process.
Conclusion
- Pre-training is critical for model performance and can reduce labeled data requirements (improving sample efficiency by up to 200x). They also found that pre-training on HTML/code was not needed in order to perform well on understanding HTML.
- Model architecture is the second most important factor and T5 models with bidirectional attention and an encoder-decoder architecture perform the best. The bidirectional attention might allow the model to process HTML from both directions and avoid the loss of information when converting the HTML tree into a sequence.
- Increasing model size does not yield significant gains in performance and should be considered in the context of the application and cost restraints.
- The HTML understanding tasks (interacting with the HTML) are difficult for websites with lots of HTML due to LLMs limited window size.