In Fast R-CNN, the computational cost is dominated by region proposal (which runs on CPU). Faster R-CNN uses a region proposal network to predict proposals from features instead of using selective search (and achieves better results). Otherwise, it is the same as Fast R-CNN. It is very fast and can run in real-time.
Faster R-CNN is a two-stage object detector.
- First stage: run once per image
- Backbone network
- Region proposal network
- Second stage: run once per proposed region
- Crop features: RoI pool or RoI align
- Predict object class
- Predict bounding box offset
Note that only a certain number of the predicted proposals are passed onto the second-stage from the region proposal network (choosing the top proposals based on their “objectness” scores). Additionally, we predict bounding box transforms for both the proposals and to get the output boxes. This gives the model two chances to correct any mistakes.
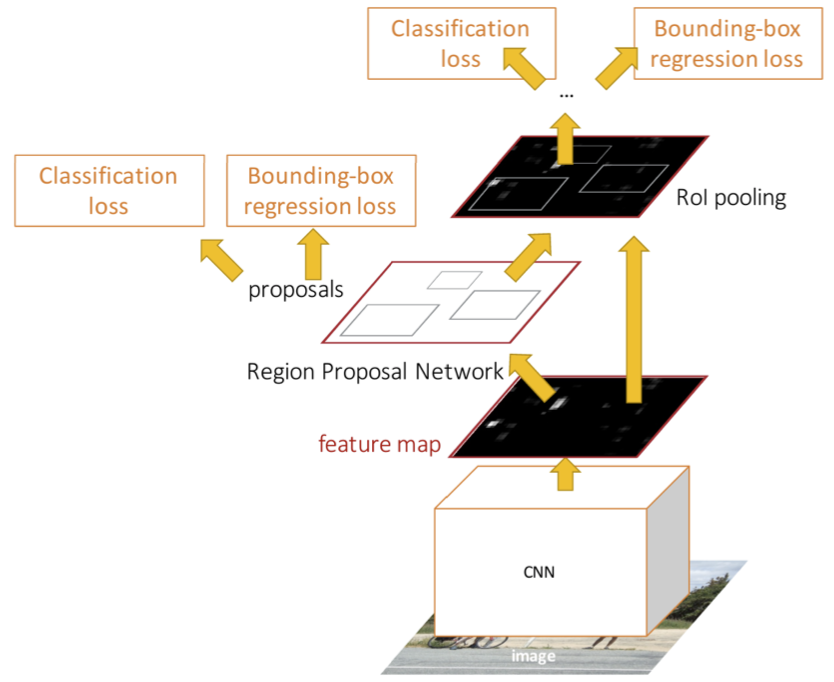
Pipeline
- The CNN backbone processes the entire image and gives a feature map
- The region proposal network (RPN) predicts regions based on the feature map
- Use RoI Align to produce per-region features (extracted from the feature map)
- Use lightweight per-region networks to classify regions and predict bounding box regression.
Losses The network will now have four different losses:
- RPN classification: classification loss for the region proposal (whether the region does/doesn’t contain an object - not actually predicting the final classification label).
- RPN regression: bounding-box regression loss for region proposal (for proposals that correspond to an anchor classified as an object - aka positive anchor). This compares the region proposal with the ground truth bounding box.
- Object classification: loss for object classifier (is it a dog, cat, etc)
- Object regression: bounding-box regression loss for object classifier (where proposed bounding box should be shifted to). This is also applicable for positive bounding boxes only. Regresses from the proposal box to the final output box of the model. This compares the final output bounding box to the ground truth bounding box.
Region Proposal Network
Faster R-CNN uses a region proposal network instead of using a heuristic to decide what regions to look at. The region proposal network will look at features extracted from the backbone network.
Anchors
 After passing the input image through the backbone, you end up with a feature map. For instance, in the above example, a 640x480 RGB image was passed through a CNN to generate a 5x6 feature map with 512 channels. Each feature in the feature map corresponds to a point in the original input image (based on the receptive field). Each of these points are called anchors.
After passing the input image through the backbone, you end up with a feature map. For instance, in the above example, a 640x480 RGB image was passed through a CNN to generate a 5x6 feature map with 512 channels. Each feature in the feature map corresponds to a point in the original input image (based on the receptive field). Each of these points are called anchors.
Predict anchors as object/no object
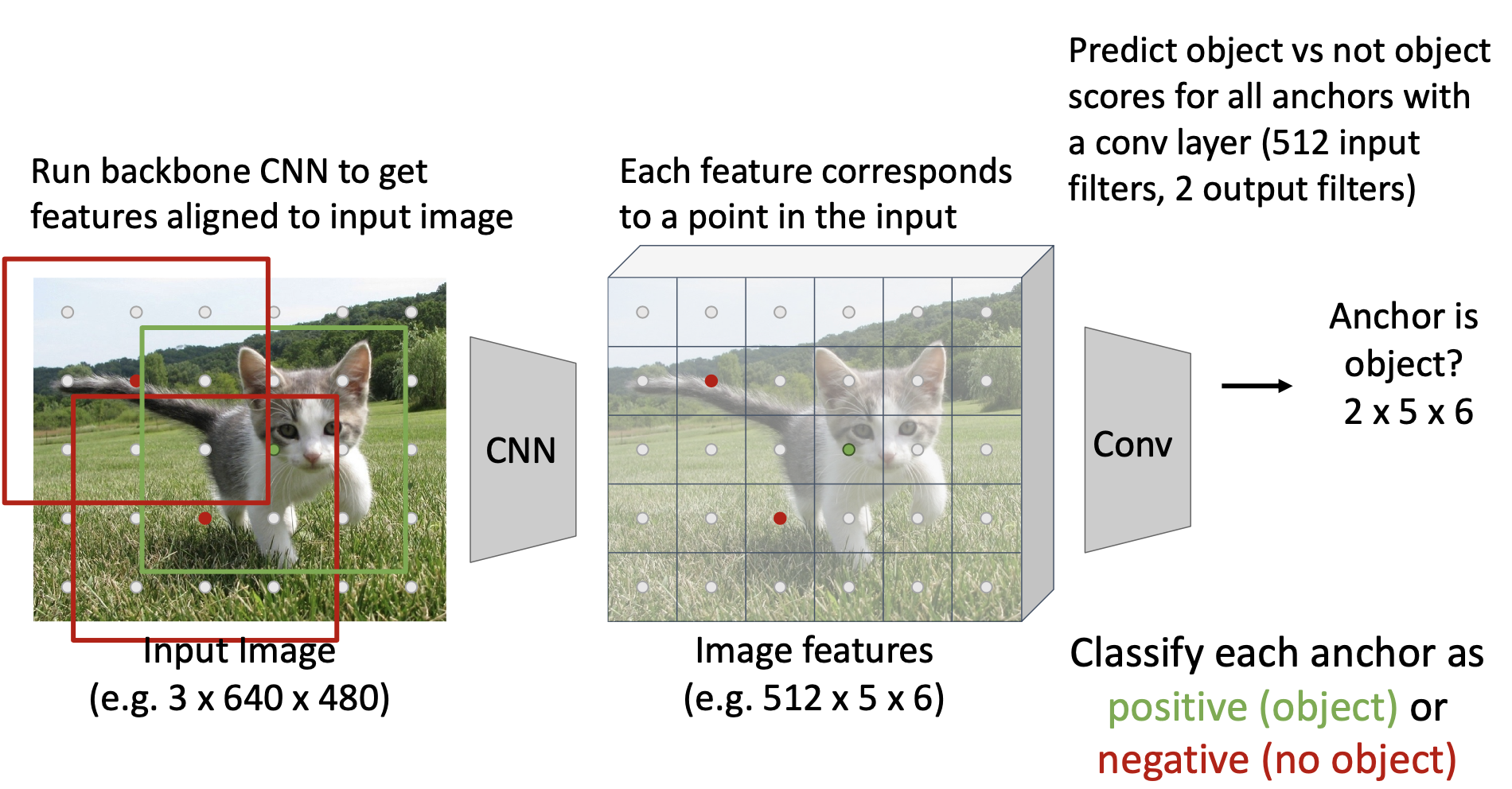 For every point in the feature map, you have a corresponding anchor of fixed size centered at the feature. These bounding boxes of fixed sizes and aspect ratios are called anchors. Each anchor corresponds to a certain region in the original input image. You then want to classify whether each of the anchors contains an object or doesn't contain an object.
For every point in the feature map, you have a corresponding anchor of fixed size centered at the feature. These bounding boxes of fixed sizes and aspect ratios are called anchors. Each anchor corresponds to a certain region in the original input image. You then want to classify whether each of the anchors contains an object or doesn't contain an object.
In the above example, this is done by having an additional Conv layer that takes the 512x5x6 feature map as input and then outputs a 2x5x6 prediction. Each location in the 5x6 grid will then have a prediction for it being an object and a prediction for it not being an object. This could theoretically be done with just a single score (ex. predict object score and then not-object score = 1 - object score), but most implementations predict both object/not object.
You can then use a binary cross entropy loss on these binary classifications (object or not object).
Predict transform to convert anchor box to GT box
![]() For the positive anchors (anchors that correspond to a ground truth bounding box), you also want to predict a transform to convert the anchor box to the ground truth box.
For the positive anchors (anchors that correspond to a ground truth bounding box), you also want to predict a transform to convert the anchor box to the ground truth box.
During training, you only need to predict this transform for the positive anchors that actually correspond to ground truth boxes. However, during inference, you don’t know whether the positive anchor actually is correct or not, so you predict the transform for all positive anchors (note that positive anchor just means it is predicted to contain an object - not that it actually does).
In the above example, the transform is predicted with an additional convolutional network (could be a seperate branch or just additional channels for the objectness head). For each of the 5x6 positions in the feature map, the corresponding output has 4 channels.
Predicting multiple anchor boxes
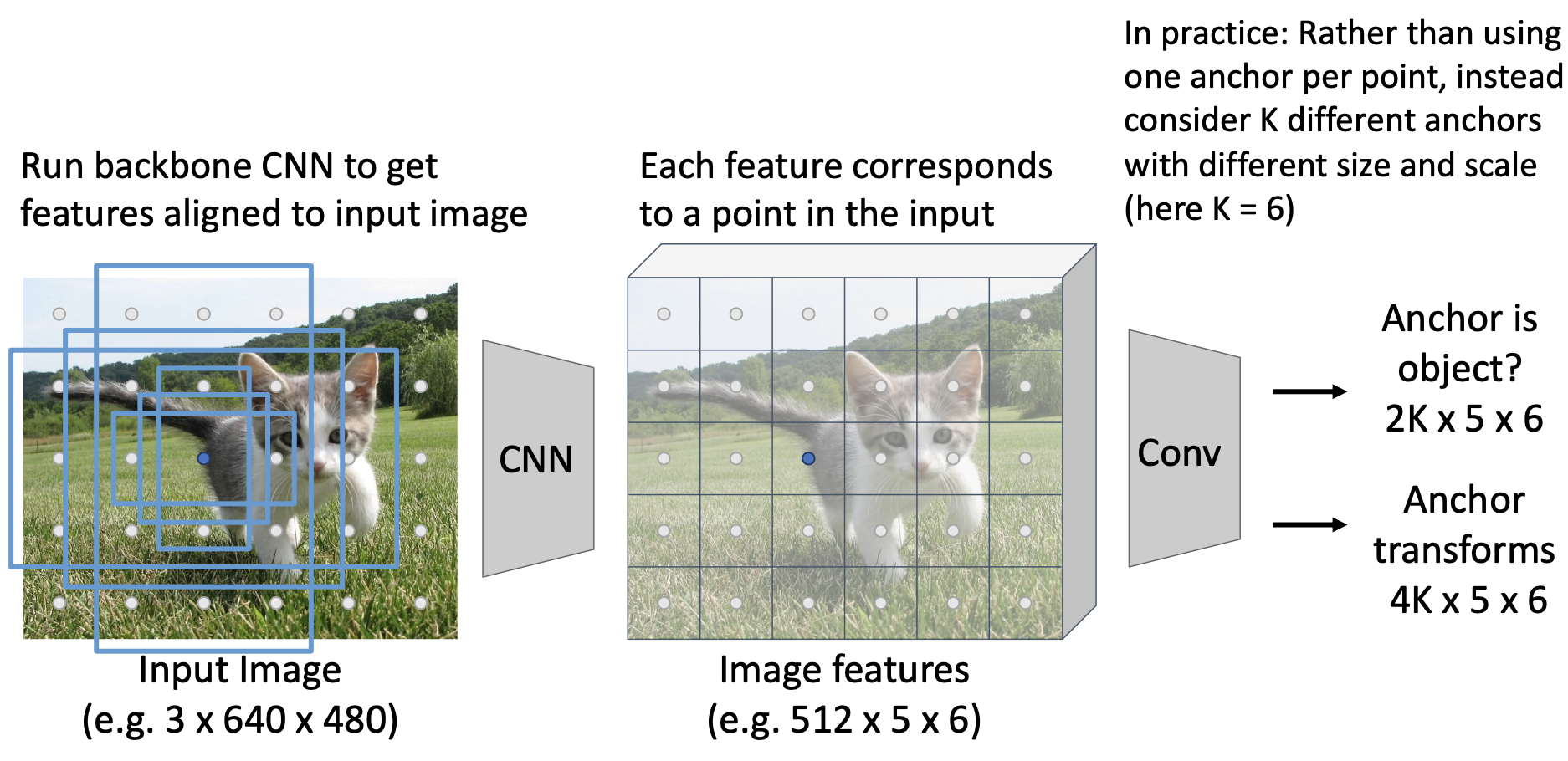
Instead of just predicting one anchor box, most implementations will predict different size anchor boxes (in example above and there are 6 blue anchor boxes shown). This results in the object/not object predictions being of size . The transforms will then be size .
Positive/negative/neutral anchors
Classification criteria:
- Positive anchors:
- Any anchor box with IoU with any ground truth box
- For each ground truth box, the anchor box with the highest IoU with the ground truth box
- Negative anchors: IoU with all ground truth boxes.
- Neutral anchors: between and IoU with all ground truth boxes.
Training usage:
- Positive anchors:
- Supervise the object classification score.
- Supervise the predicted proposal transform (use the difference between the predicted anchor transform and what the actual anchor transform should be to update the loss)
- Negative: supervise only the object classification score.
- Neutral: ignore
Test time: At test time you don’t know whether something is actually positive/negative/neutral. You will therefore sort all predicted anchor boxes ( anchor boxes predicted per feature in the feature map) and take the top (ex. ) as the region proposals.
RPN Additional Information
- RPN Hyperparameters: How many bounding boxes you use, the bounding box sizes, and how many proposals you keep are all hyperparameters you need to choose.
- RPN is translational invariant. Doesn’t get x, y coordinates. Just slides filters over the image filters (translational invaraint). However, zero padding will break translational invariance.
Box Terms We have four different types of boxes involved in Faster R-CNN:
- Ground truth: these are the boxes labelled by an annotator
- Anchor box: these are the boxes of fixed sizes that are centered on each feature
- Proposal boxes: these are predicted by the region proposal network. These are formed by applying a predicted transform to the anchor boxes.
- Output boxes: these are predicted by the final per-region network. These are formed by applying a predicted transform to the proposal boxes.
Note: the model has two chances to predict a transform to modify the anchor boxes of fixed size to become the final predicted output boxes