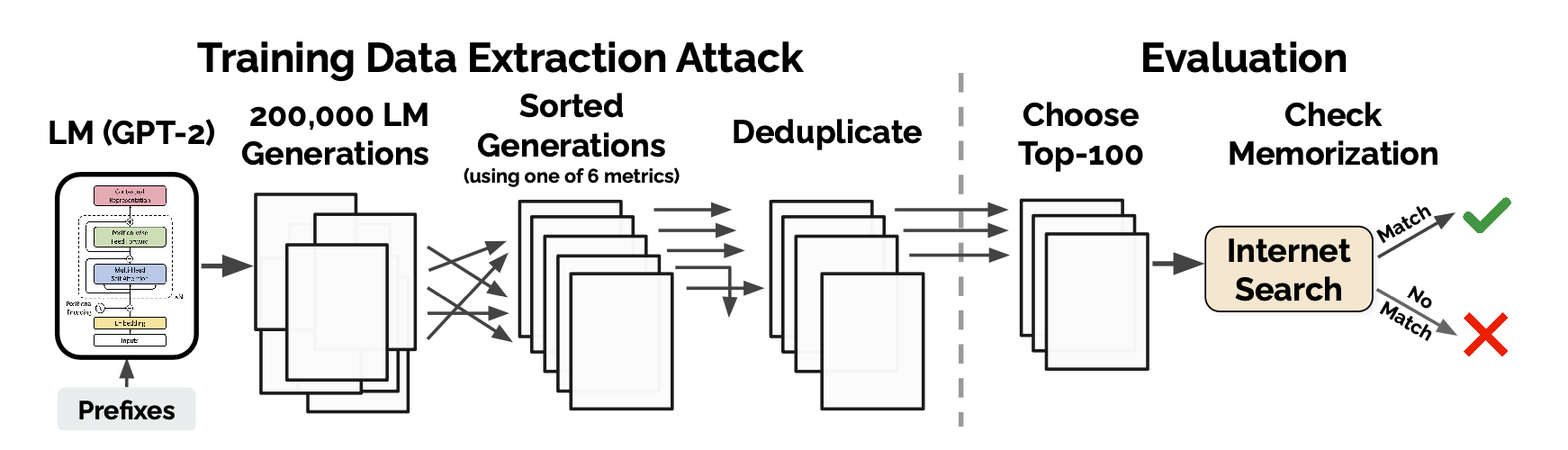
The paper conducts a training data extraction attack to recover individual training examples by querying GPT-2. They generate 3 datasets of 200,000 samples each from GPT-2 using one of three strategies (top-n, temperature decay, and internet - these are all described below) and then rank the datasets according to six different metrics (described below). For each of the 3 x 6 = 18 configurations, they select 100 samples from the top-1000 samples according for each of the metrics and then manually check the GPT-2 dataset (which is public) to see if the samples match training data (manually checking 100 * 18 = 1,800 total examples).
Background
LLMs
A language model is trained to maximize the probability of the data in a training set
X. Because of this training setup, the “optimal” solution to the task of language modeling is to memorize the answer to the question “what token follows the sequence ?” for every prefix in the training set. However, state-of-the-art LMs are trained with massive datasets, which causes them to not exhibit significant forms of memorization: empirically, the training loss and the test loss are nearly identical
GPT-2
The paper chose to use GPT-2 because the model and the training data are already public so publishing the experiment results wouldn’t cause harm.
The GPT-2 family of models were all trained using the same dataset and training algorithm but with different model sizes. GPT-2 uses a byte pair encoder (BPE) to compress its dataset. They represent text as bytes so you only have to work with an alphabet consisting of 256 possibilities vs. needing a much larger starting alphabet if you used unicode.
The dataset was collected by following outbound links from Reddit and then cleaning and de-duplicating the HTML.
Details on BPE from the paper
We observed BPE including many versions of common words like dog since they occur in many variations such as ”
dog.,dog!,dog?. This results in a sub-optimal allocation of limited vocabulary slots and model capacity. To avoid this, we prevent BPE from merging across character categories for any byte sequence. We add an exception for spaces which significantly improves the compression efficiency while adding only minimal fragmentation of words across multiple vocab tokens.
Types of Privacy Attacks
Membership inference attack: Try to predict whether a specific example was used to train the model. For instance, if you wanted to check if OpenAI used your code to train it’s model, you could conduct a membership inference attack.
Leakage via membership inference attacks is typically associated with overfit models where the model is trained on the same example for multiple epochs. People mistakenly believed that since SOTA LMs are trained for a single epoch on a massive, de-deduplicated dataset that they won’t overfit and will have little risk of membership inference attacks working. This paper shows that even SOTA LMs do leak individual training examples.
Model inversion attack: Reconstruct representative views of a subset of examples. For instance, if you train a face recognition model, a model inversion attack might try to recover a fuzzy image of a particular person that the classifier can recognize.
How is this different than a membership inference attack?
In a membership inference attack you already have the exact training example. In a model inversion attack you don’t have the examples and are trying to reconstruct a rough idea about them.
Training data extraction attacks Like model inversion attacks, reconstruct training datapoints. However, training data extraction attacks aim to reconstruct verbatim training examples and not just representative “fuzzy” examples. This makes them more dangerous, e.g., they can extract secrets such as verbatim social security numbers or passwords.
Protecting Privacy
An approach to minimizing memorization of training data is to apply Differentially Private Training techniques. Unfortunately, training models with differentially-private mechanisms often reduces accuracy because it causes models to fail to capture underrepresented data. It also increases training time, which can further reduce accuracy because current LMs are limited by the cost of training.
Defining Memorization
The paper defines eidetic memorization as a particular type of memorization. It says a string is -Eidetic Memorized if it is extractable from a language model given a short prefix and appears in at most examples in the dataset. For GPT-2, each webpage counts as a single training example so a string may appear many times on one page while still counting as memorization.
Note
“Eidetic memory (more commonly called photographic memory) is the ability to recall information after seeing it only once.”
Threat Model
The paper considers an adversary who is able to see the probability of arbitrary sequences of outputs but is not able to inspect individual weights or hidden states of the model. This matches what a user of the OpenAI API would be able to achieve.
Example of getting the
logprobsfor each word from the ChatGPT API"id": "chatcmpl-123", "object": "chat.completion", "created": 1702685778, "model": "gpt-3.5-turbo-0613", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "Hello! How can I assist you today?" }, "logprobs": { "content": [ { "token": "Hello", "logprob": -0.31725305, "bytes": [72, 101, 108, 108, 111], "top_logprobs": [ { "token": "Hello", "logprob": -0.31725305, "bytes": [72, 101, 108, 108, 111] }, { "token": "Hi", "logprob": -1.3190403, "bytes": [72, 105] } ] }, { "token": "!", "logprob": -0.02380986, "bytes": [ 33 ], "top_logprobs": [ { "token": "!", "logprob": -0.02380986, "bytes": [33] }, { "token": " there", "logprob": -3.787621, "bytes": [32, 116, 104, 101, 114, 101] } ] }, ... ] }, "finish_reason": "stop" } ], "usage": { "prompt_tokens": 9, "completion_tokens": 9, "total_tokens": 18 }, "system_fingerprint": null
The adversary wants to extract as much training data from the possible and a stronger attack will extract more total examples with lower values of . It is not important what data is extracted.
Building the dataset
The paper used three different strategies for building a dataset.
Top-N Sampling
An LLM generates new text by predicting the next token conditioned on a possibly empty prefix () and then feeding back into the model to sample conditioned on . This process is repeated until a stopping criterion is reached.
A naive approach to select the next token is to greedily select the most-probable token at each step. However, you can get more diverse results if you use Top-K (or Top-N) sampling where you set all but the top-n probabilities to zero and then renormalize the probabilities before sampling the next token from this distribution.
Temperature Scaling
At each step of generating an output sequence, the model predicts a logit tensor and then computing a probability distribution over all possible tokens via softmax(z). You can “flatten” this distribution by replacing softmax(z) with softmax(z/t) for where is called the temperature. A higher temperature causes the model to be less confident and have more diverse output. See the diagram below for the effects of different on a distribution. Also see softmax with temperature scaling.
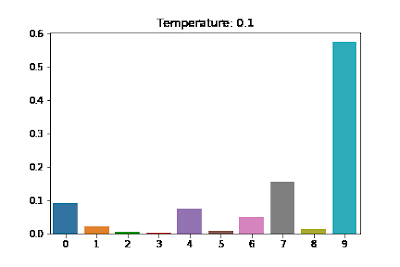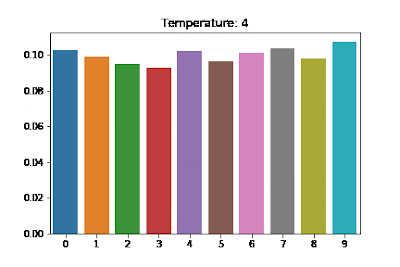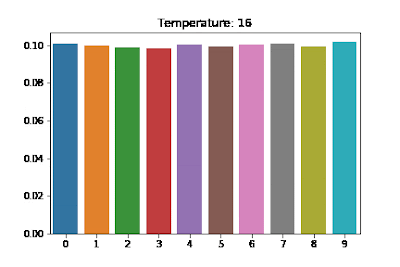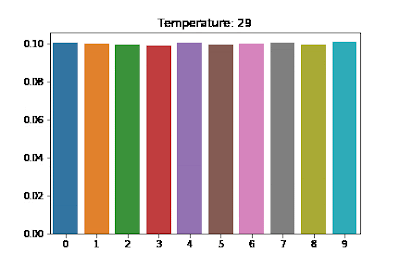
The paper starts out with a high temperature and then decays it over time (using a lower temperature for tokens later in the sequence).
Details on why the paper uses temperature decay and not a single temperature value
Maintaining a high temperature throughout the generation process would mean that even if the sampling process began to emit a memorized example, it would likely randomly step off the path of the memorized output. Thus, we use a softmax temperature that decays over time, starting at t = 10 and decaying down to t = 1 over a period of the first 20 tokens (≈10% of the length of the sequence). This gives a sufficient amount of time for the model to “explore” a diverse set of prefixes while also allowing it to follow a high-confidence paths that it finds.
Internet
The paper was concerned that there were some prefixes that were unlikely to be sampled but still occurred in the actual data. They created their own dataset from Common Crawl (and not the Reddit based dataset GPT-2 used) and then seeded the model with prefixes from this dataset.
Membership Inference Metrics
• Perplexity: the perplexity of the largest GPT-2 model. • Small: the ratio of log-perplexities of the largest GPT-2 model and the Small GPT-2 model. • Medium: the ratio as above, but for the Medium GPT-2. • zlib: the ratio of the (log) of the GPT-2 perplexity and the zlib entropy (as computed by compressing the text). • Lowercase: the ratio of perplexities of the GPT-2 model on the original sample and on the lowercased sample. • Window: the minimum perplexity of the largest GPT-2 model across any sliding window of 50 tokens.
Perplexity
Perplexity tells you how confident the model was about the sequence of tokens it predicted. This metric could be useful because if GPT-2 was more confident about its predictions, then it was possibly more likely to have seen the sequence it predicted in the training data.
Small / Medium
Just filtering out samples with low likelihood has poor precision (tp/(tp + fp)) because of many false positives where samples are assigned a high likelihood but they aren’t actually interesting. The main categories of these types of examples are:
- Trivial memorization: ex. repeating the numbers from 1 to 100
- Repeat substrings: a failure mode of LMs is they often repeat the same string over and over (ex. “I love you. I love you…” is a sequence that is not memorized but has a high likelihood).
The paper thought they could filter out these uninteresting (yet still high-likelihood samples) is to filter out samples where an original model’s likelihood is much higher than another model that also captures text likelihood.
Small/Medium: they need a second language model to compare likelihoods of sequences with. They could train a model on a different set of examples but an easier strategy is to use a smaller model trained on the same dataset because a smaller model has less capacity for memorization. They use the small and medium GPT-2 models for this and compare the log of the perplexities of these models with the original model.
zlib
zlib is a text compression algorithm. Here is an example of using it to compress text in Python:
>>> import zlib
>>>
>>> original_data = b"This is the original text we want to compress."
>>>
>>> compressed_data = zlib.compress(original_data)
>>> compressed_data
b'x\x9c\x0b\xc9\xc8,V\x00\xa2\x92\x8cT\x85\xfc\xa2\xcc\xf4\xcc\xbc\xc4\x1c\x85\x92\xd4\x8a\x12\x85\xf2T\x85\xf2\xc4\xbc\x12\x85\x92|\x85\xe4\xfc\xdc\x82\xa2\xd4\xe2b=\x00\x89\x9a\x10\xe3'
>>> decompressed_data = zlib.decompress(compressed_data)
>>> decompressed_data
b'This is the original text we want to compress.'From the paper:
“We compute the zlib entropy of the text: the number of bits of entropy when the sequence is compressed with zlib compression.”
A breakdown of what this means is:
- “the number of bits of entropy”: entropy can be quantified in bits. One bit of entropy represents two equally likely outcomes, like a coin toss. The more bits of entropy, the more information is required to describe the text, or the more unpredictable the text is.
- “when the sequence is compressed with zlib compression”: The idea is that by compressing the text with zlib, one can measure how much the text can be reduced in size. The less it can be compressed, the higher the entropy; this is because high-entropy text has less redundancy and is less predictable, so compression algorithms have a harder time finding patterns to reduce the size.
A high entropy string would be one that appears random with no discernible pattern or repetition, making it difficult to compress. A low entropy string, on the other hand, has a lot of repetition or a clear pattern, making it more predictable and easier to compress.
Example of a Low Entropy String: A low entropy string could be a sequence with lots of repetition or a simple pattern:
"AAAAAAAAAAAAAAAAAAAAAAA"
"12312312312312312312312"
These strings have low entropy because they are very predictable and can be highly compressed. A compression algorithm could easily represent these strings with a rule like “repeat ‘A’ 30 times” or “repeat ‘123’ 10 times.”
Example of a High Entropy String: A high entropy string would look more random, with no obvious pattern or repetition:
"j8J9!kDl2^fLs@1pEo4#rTz"
This string appears to have high entropy because it consists of a mix of uppercase and lowercase letters, numbers, and special characters in a seemingly random order. It would be less compressible because there’s no clear way to simplify or predict the sequence of characters.
And indeed the more random string is longer after it is compressed:
>>> zlib.compress(b"AAAAAAAAAAAAAAAAAAAAAAA")
b'x\x9cst\xc4\n\x00F+\x05\xd8'
>>> zlib.compress(b"j8J9!kDl2^fLs@1pEo4#rTz")
b'x\x9c\xcb\xb2\xf0\xb2T\xccv\xc91\x8aK\xf3)v0,p\xcd7Q.\n\xa9\x02\x00T/\x07C'Lowercase
They use the ratio of the perplexity of the same model on the sample before and after lowercasing it. Lowercasing the text can dramatically alter the perplexity of memorized content that expects a particular casing.
Sliding Window
If you have a chunk of memorized text surrounded by non-memorized (and high perplexity) text, then the overall perplexity will be higher and be considered less likely as memorized. For example, if the model memorized someone’s social security number: XXX-XXX-XXXX, and it output the sequence:
asediyflaiysrfiwluyi my ssn is XXX-XXX-XXXX doqfpr9qy8r9qpywp9yqyqo
the entire sequence would have a higher perplexity than just my ssn is XXX-XXX-XXXX.
To address this, they use the minimum perplexity when averaged over a sliding window of 50 tokens.
Results
The following table shows the number of memorized examples (out of 100 candidates) identified using each combination of text generation strategy and six membership inference techniques:
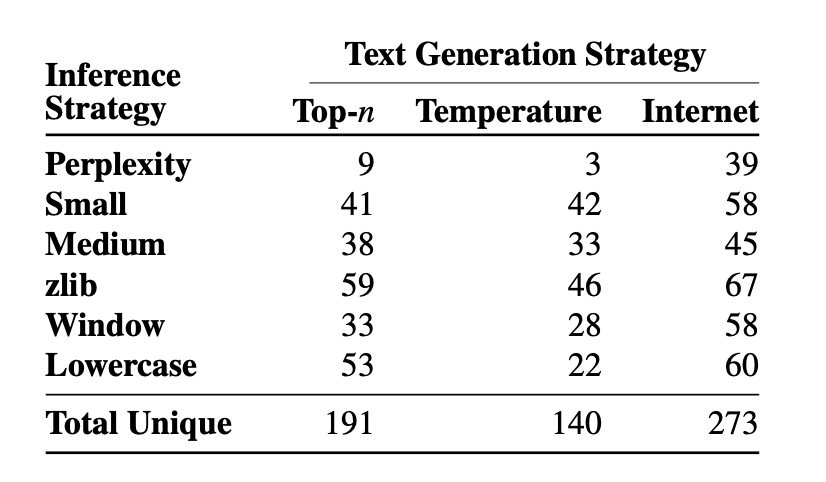
In total, 604 out of the 1,800 samples were memorized (true positive rate of 33.5%).
They were also able to extract longer snippets by using a Beam Search decoding method instead of greedy decoding which often fails to generate long verbatim sequences.