A byte pair encoder works by iteratively merging the most frequent pair of bytes in the input text to create a new token or subword unit. This process helps in reducing the vocabulary size and capturing the underlying patterns and structures in the text data, which is crucial for training and improving the performance of LLMs.
Training Algorithm
Let vocabulary be the set of all individual characters = {A, B, C, D,…, a, b, c, d…}.
Repeat:
- Choose the two symbols that are most frequently adjacent in the training corpus (say ‘A’, ‘B’)
- Add a new merged symbol ‘AB’ to the vocabulary
- Replace every adjacent ‘A’ ‘B’ in the corpus with ‘AB’. Repeat until k merges have been done.
Note: you often add a special end-of-word symbol _ before each space and then separate the document into letters and _.
Example Training:
You start with the corpus:
low low low low low lowest lowest newer newer newer
newer newer newer wider wider wider new new
The most frequent tokens that appear next to each other is “e” and “r” so you merge them and add a new token “er”.
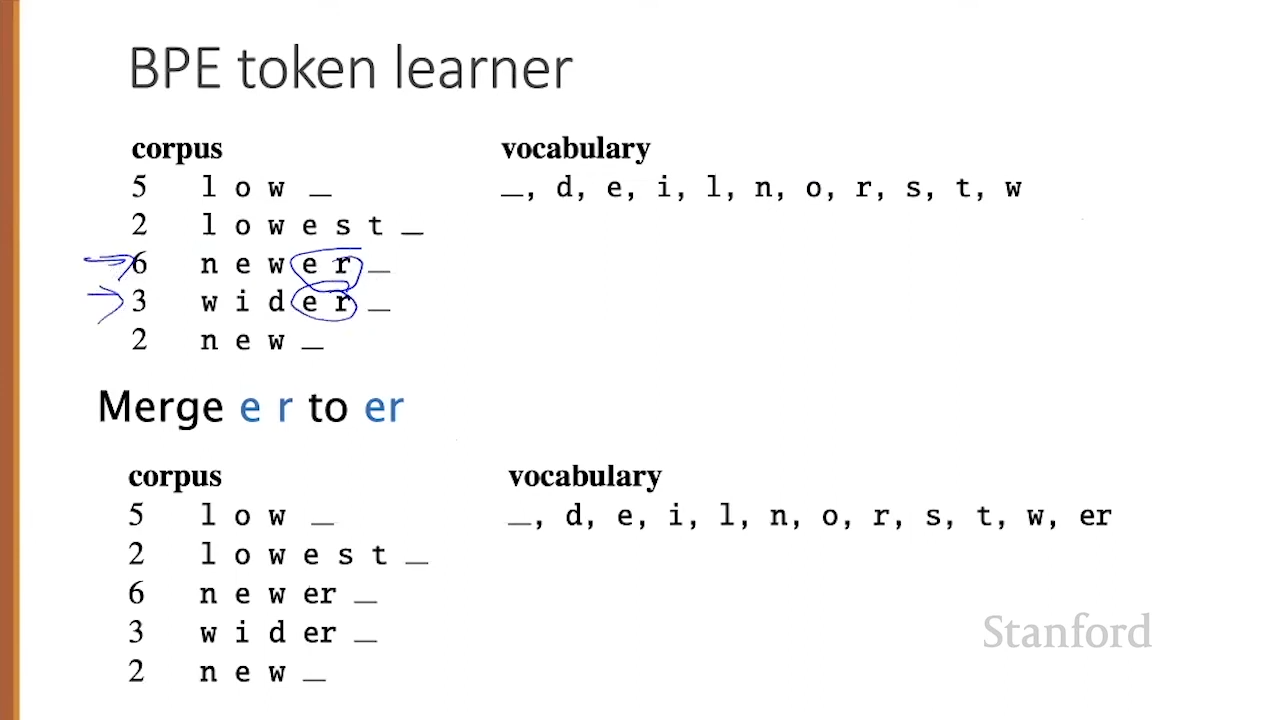
You then merge the token “er” and _ and add a new token “er_“.
Inference Algorithm
On the test data you run each merge learned from the training data:
- Greedily (run it as many times as possible)
- In the order we learned them during training (ignore frequencies of the test data).
Properties of BPE tokens:
A morpheme is the smallest meaning-bearing unit of a language (ex. “unlikeliest” has 3 morphemes - “un”, “likely”, “est”).