What’s the difference between GANs and normalizing flows?
GANs are trained to take a random vector (ex. sampled from Gaussian noise) and produce a data point (ex. an image) via a generator that produces images and a discriminator that judges the quality of these. Normalizing flow models are trained to take a data point (ex. an image) and produce a simple distribution (ex. Gaussian) that minimizes the log-likelihood of the probability of the transformed samples. At inference time for GANs you use the same procedure as for training and sample noise and then pass it to a generator to produce an image. For normalizing flow models, the entire model is invertible so you use a reverse process to what you used during training and sample from noise to produce an image.
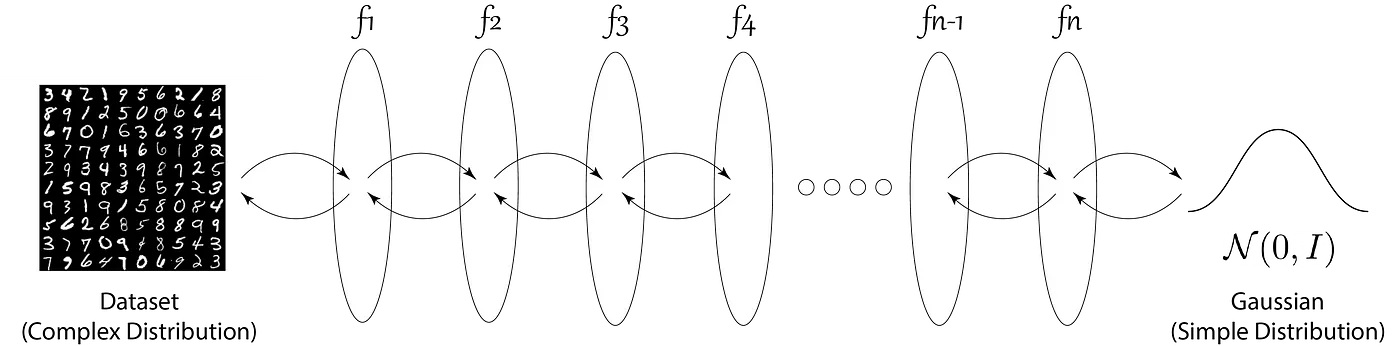
Different from autoregressive model and variational autoencoders, deep normalizing flow models require specific architectural structures.
- The input and output dimensions must be the same.
- The transformation must be invertible.
- Computing the determinant of the Jacobian needs to be efficient (and differentiable). This is due to the change of basis formula. See youtube for more details.
Math
In simple words, normalizing flows is a series of simple functions which are invertible, or the analytical inverse of the function can be calculated.
What is an invertible function
For example, is a reversible function because for each input, a unique output exists and vice-versa whereas is not a reversible function because both can correspond to either 3 or -3. The inverse of exists if and only if is a Bijective Function (maps each input to exactly one output and vice-versa).
Let be a high-dimensional random vector with an unknown true distribution . We collect an i.i.d. dataset , and choose a model with parameters .
In the context of a dataset of images, would represent a high-dimensional vector that encodes the pixel values of an image. Each element of the vector corresponds to a pixel in the image, and the dimensionality of the vector is equal to the total number of pixels in the image. The true distribution would represent the distribution of all possible images that could be generated from the dataset (this is unknown), and the goal of a flow-based generative model would be to learn a model that can generate new images that are similar to the images in the dataset.
The dataset being i.i.d. means it is “independent and identically distributed.” In the context of an image dataset, it means that the presence of one image doesn’t affect the probability of the next image and each image has the same likelihood. Stats Stack Exchange Post.
In case of discrete data , the log-likelihood objective is then equivalent to minimizing:
This is taking the average (summing over all examples and then dividing by the number of examples ) of the negative log of the probability that your learned model produces training example .
Optimization is done through stochastic gradient descent using minibatches of data.
In most flow-based generative models the generative process is defined as:
where:
- is the latent variable
- has a simple density (ex. a 0-1 normal distribution).
- is an invertible (aka bijective) function that to produce a latent variable , you compute . This means is the inverse of .
What is a latent variable?
A latent variable, in the context of statistics and data analysis, is a variable that is not directly observed but is inferred or estimated from other observed variables.
During the training process of the model, you take an image and then pass it to the inverse of which is (you are learning the model during training). then produces which is a vector that belongs to the simple density function you are trying to learn. For instance, if your density function has dimension = 256, then will produce a vector of dimension = 256 that corresponds to the images representation in the density function space.
We focus on functions where (and, likewise, ) is composed of a sequence of transformations such that the relationship between and can be written as:
This just means that you compose a series of invertible functions in a sequence such that you can take to in a way that you can then perform the inverse computation.
Such a sequence of invertible transformations is also called a (normalizing) flow
Under the change of variables formula, the probability density function (pdf) of the model given a datapoint can be written as:
which means that the log probability of a datapoint is equivalent to something you can represent in terms of the log probability of the simple distribution of your latent variable .
You can therefore represent the log-likelihood objective you are minimizing as:
which is equivalent to:
which is useful since you can find out the probability of a point from a normal distribution while you couldn’t find out the probability of an image () so you can now actually calculate your objective.