The autonomous vehicle problem is often divided into perception, prediction, and planning. This works well when the tasks are independent, but prediction and planning are not independent since hero’s actions may significantly impact the behavior of other agents and the behavior of other agents may significantly change what a good plan is. Previous approaches mostly focused on predicting independent futures for each agent based on past motion and planning against the independent predictions. However, this makes it challenging to represent the future interaction possibilities between different agents. This paper introduces a model to predict the behavior of all agents jointly to produce consistent futures that account for interactions between agents.
The main contributions are:
- A novel, scene-centric approach that allows gracefully switching between training the model to produce either marginal (independent agent trajectories) and joint (full scene) agent predictions in a single feed-forward pass.
- They have a Transformer-based model architecture that uses attention to combine features across road elements, agent interactions, and time steps.
- They use a masked sequence model that enables them to condition on hypothetical agent futures at inference time, enabling conditional motion prediction or goal conditioned prediction.
Marginal vs. Joint Prediction
Joint probability is the probability of two events occurring simultaneously. Marginal probability is the probability of an event irrespective of the outcome of another variable. Marginal agent predictions may conflict with each other (have overlaps), while consistent joint predictions should have predictions where agents respect each other’s behaviors (avoid overlaps) within the same future.
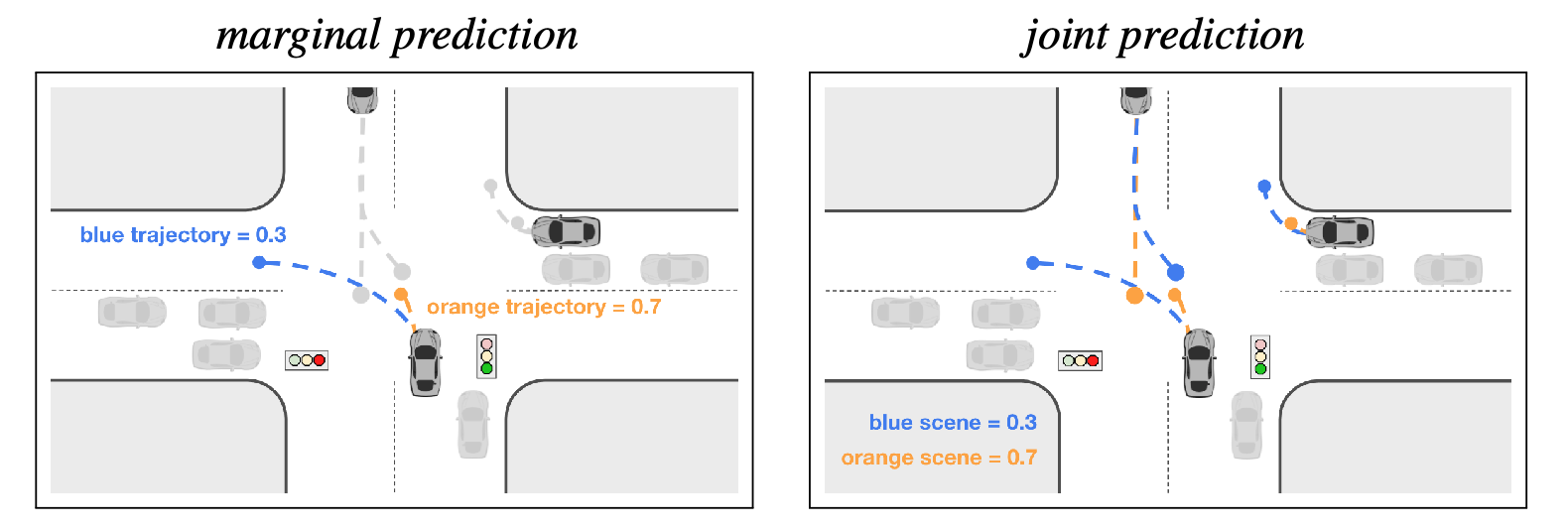
Left: Marginal prediction for bottom center vehicle. Scores indicate likelihood of trajectory. Note that the prediction is independent of other vehicle trajectories. Right: Joint prediction for three vehicles of interest. Scores indicate likelihood of entire scene consisting of trajectories of all three vehicles.
Related Work
One popular approach to prediction is to render inputs as rasterized multi-channel top-down image and capture relationships between scene elements using convolutional deep architectures. However, the local structure of receptive fields make it difficult to capture spatially-distant interactions.
An alternative is to use an entity-centric approach. Agent state history is typically encoded via sequence modeling techniques like RNNs. Modeling relationships is done via pooling, soft-attention, or GNNs.
Scene-centric versus agent-centric representations
This section of the paper was quite unclear (as agreed by the reviews on OpenReview).
Scene Centric (top-down rasterized view): Some models do a majority of modeling in a global, scene-level coordinate frame, such as work that employs a rasterized top-down image. This has an efficiency benefit of being able to use a single representation of the world state in a common coordinate frame. However, it has the downside of being not being pose invariant (the representation is centered on hero so the representation will change depending on hero’s orientation and the orientation of other agents with respect to hero).
Scene-centric representations aren't pose invariant.
This is because the representation is fixed with respect to hero so the representation will change depending on hero’s orientation and the orientation of other agents with respect to hero. In the below diagram, hero moved but the other agents stayed in the same location, but the representation still changes for everything. scene-centric-hero-moving.excalidraw
Agent coordinate frame (no rasterization and relations are given with respect to each agent): For each agent in the scene you need to model the entire world with reference to that agent. That means you would have to encode all features and other vehicles’ distance to each agent individually. This has the benefit of being pose-invariant, but the computations scales linearly with the number of agents and quadratically with the number of pairwise interactions between agents.
Agent-centric with representations in a global frame (no rasterization and relations are given with respect to hero): The paper encodes information about the world and agents with reference to the agent of interest (for the Waymo Open Motion Dataset, this is the ego vehicle, and in Argoverse this is the agent the task asks them to predict). The outputs are all with respect to the ego vehicle in the scene. All inputs and outputs range from -100 meters to 100 meters in X and Y.
Not rasterizing the scene allows the paper to keep high-fidelity state representations. Additionally, they can include agents that are very far away from hero without the memory requirements blowing up. Finally, keeping the relationships with respect to the ego vehicle in the scene makes it so they can use their masked attention approach (described below) with a tensor of shape where all values are in the same coordinate frame.
This approach is not pose-invariant.
Representing multi-agent futures
One way to represent multiple possible futures for an agent is via a weighted set of trajectories per agent. You could also take a similar approach to ImplicitO which uses Backwards Flow to have multiple possible futures for a single agent using just one flow vector per grid cell in a top-down grid.
This paper takes the approach to predict a set of distinct joint futures with associated likelihoods.
Approach
They use a scene-centric representation for all agents to allow scaling to a larger number of agents in a dense environment. Their architecture alternates attention between dimensions representing time and agents across the scene.
Overview
The Scene Transformer has three stages:
- Embed the agents and the road graph into a high dimensional space.
- Use an attention-based network to encode the interactions between agents and the road graph.
- Decode multiple futures using an attention-based network.
Masked Attention
They use a single model architecture for multiple motion prediction tasks by using masking (different masking strategies define distinct tasks). The left column is the current time (t0) and the top-row represents hero (AV).
scene-transformer-masked-attention.excalidraw
Input Representation
The key representation in the model is a 3-dimensional tensor of agents with feature dimensions across time steps. At every layer within the architecture they use a representation of shape or when decoding across possible futures. Each task (motion planning, conditional motion prediction, and goal-conditioned prediction) can be formulated as a query with a specific masking strategy by setting the indicator mask (1 = hidden, 0 = visible) to 0 to provide that data to the model. The goal of the model is to fill in the masked data. This approach is similar to the one used by BERT.
They generate the features:
- A set of features for every agent time step if that time step is visible
- A set of features for the static road graph, road elements static in space and time, learning one feature vector per polyline.
- A set of features for the dynamic road graph, which are road elements static in space but dynamic in time (e.g. traffic lights).
All three categories have position information, which they preprocess to center and rotate around the agent of interest (ego for WOMD and agent to predict for in Argoverse) and then encode the positional information with sinusoidal position embeddings.
Factorized Self-Attention
Naive attention across agents and time A naive approach to using a transformer for multiple time steps would be to have tokens for all the agents across all time steps fed to the model.
However, this has the issue of identity symmetry since no specific agent identification information is added, so two agents (blue and yellow) of the same type with the same type with the same masked future time-step (two black rectangles) will have identical input representations to the transformer at their masked timestep and therefore the transformer will fill in the masked values with the same information.
scene-transformer-agent-tokens-across-time.excalidraw
Factorized self-attention: The paper alternates performing attention across either time or agents. Attention only across time allows the model to learn smooth trajectories without needing to keep track of which agents is which. Applying attention only across agents allows the model to learn multi-agent interactions independent of the specific time step.
You start with an input . You always have a channel dimension of . You fold either or into your batch dimension when performing attention depending on if you want to mix time or agents.
- Attention across time: . Each agent’s temporal information is mixed separately.
- Attention across agents: . All agents are mixed together but each time step is separate.
Benefits of factorized self-attention
- It is more efficient since the attention is computed over a smaller set.
- It provides an implicit identity to each agent when performing attention across time.
Cross-attention
The model incorporates road graph information via cross-attention with queries for the agents and keys/values for the road graph.
Outputs
The outputs of the model are of form where the seven outputs come from a 2-layer MLP and correspond to:
- 3 outputs for the position of the agent at a specific timestep in meters with respect to the agent of interest.
- 3 outputs for the uncertainty for the position values.
- 1 output for the heading
Predicting probabilities for each future
The model needs to predict a probability score for each future (joint model) or agent trajectory (marginal model). To do this they add a feature representation that summarizes the scene and each agent (this is called out in the below diagram in red).
![]()
After the first set of factorized self-attention layers, they compute the mean of the agent features tensor across the agent and time dimension separately, and add these as an additional artificial agent and time making the internal representation .
The artificial agent and time step propagates through the network, and provides the model with extra capacity for representing each agent, that is not tied to any timestep.
At the final layer, they slice out the artificial agent and time step to obtain summary features for each agent:
- The additional time dimension is used for per-agent trajectory likelihoods.
- The ‘corner’ feature that is both additional time and additional agent is used for scene likelihoods.
This feature is then processed by a 2-layer MLP producing a single logit value that they use with a softmax classifier for an estimate of probabilities for each future.
Loss
For joint future predictions they only back-propagate the loss through the individual future that most closely matches the ground-truth in terms of displacement loss.
For marginal future predictions, each agent is treated independently. They select the future with minimum loss for each agent separately, and back-propagate the error correspondingly.