Main concepts introduced in framework:
- A deeply-supervised mask decoder.
- A query decoupling strategy.
- Improved post-processing method.
- Uses Deformable DETR to process multi-scale features.
Framework
Deeply-supervised mask decoder
The mask decoder is responsible for predicting binary masks and class label. During training, predictions are made using the output of each layer of the mask decoder (vs. just using the final layer’s output). The loss is calculated for all layers and this is what the paper refers to as “deep supervision”.
Some literature argue that the reason DETR is slow to converge is because the attention maps pay equal attention to all pixels in the feature map (vs. focusing on important regions). Panoptic SegFormer’s deep supervision strategy lets the attention modules quickly focus on meaningful semantic regions and capture meaningful information in earlier stages. It improves performance and reduces the number of required training epochs by half compared to Deformable DETR.
Query decoupling strategy
- Panoptic SegFormer splits it’s queries into + queries.
- is a hyperparameter that dictates the total number of instances that can be detected in an image (irrespective of the number of classes).
- is the number of “stuff” classes.
- The thing queries first pass through a location decoder while the stuff queries go directly to the mask decoder. Treating the queries differently was motivated by the belief “things” and “stuff” should be treated differently.
- The thing and stuff queries can use the same pipeline once they are passed to the mask decoder which accepts both thing queries and stuff queries and generates the final masks and categories.
- During training, ground truths are assigned via bipartite matching to thing queries. For stuff queries, a class-fixed assign strategy is used with each stuff query corresponding to one stuff category.
Post-processing method
- Post-processing strategy improves performance without additional costs by jointly considering classification and segmentation qualities to resolve conflicting mask overlaps.
- This was motivated because common post-processing (ex. pixel-wise argmax to decide on the class) tends to generate false-positive results due to extreme anomalies.
Architecture
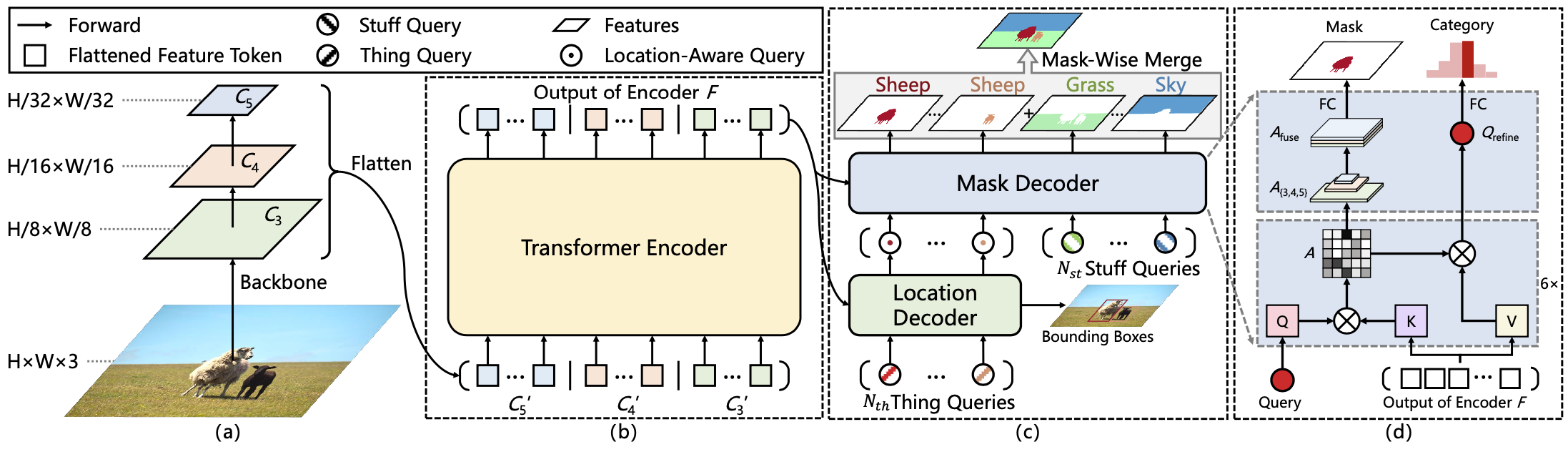 Panoptic SegFormer consists of three key modules: transformer encoder, location decoder, and mask decoder.
Panoptic SegFormer consists of three key modules: transformer encoder, location decoder, and mask decoder.
Backbone
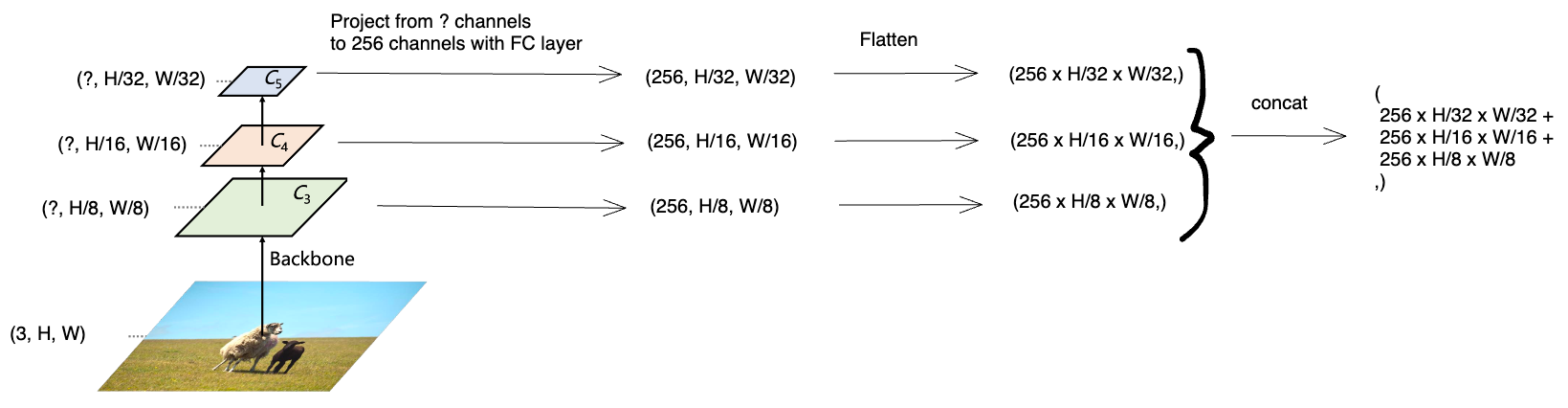
- You pass an input image to the backbone network and get feature maps from the last three stages. These have resolutions with respect to the original image.
- You then project each of the feature maps from however many channels they have (denoted with
?) to 256 channels using a 1x1 conv (the paper calls this a fully-connected layer). - You then flatten each of the feature maps and concatenate them to produce your input sequence to the encoder.
Transformer Encoder
The transformer encoder is used to refine the multi-scale feature maps sequence given by the backbone.
Because of the high computational cost of self-attention, previous transformer-based methods only processed low-resolution feature maps (ex. ResNet ) in their encoders which limited segmentation performance (higher resolution features are needed to get better results).
Panoptic SegFormer uses Deformable Attention in the transformer encoder which has a lower computational complexity (it focuses on a fixed number of locations with learned offsets vs. all locations). Therefore, they are able to use high-resolution and multi-scale feature maps.
They form tokens for each pixel in the multi-scale feature maps where each token has dimension 256. They define to be and the shapes of the flattened feature maps are . They then pass tokens to the transformer encoder where each token has length 256.
Location Decoder
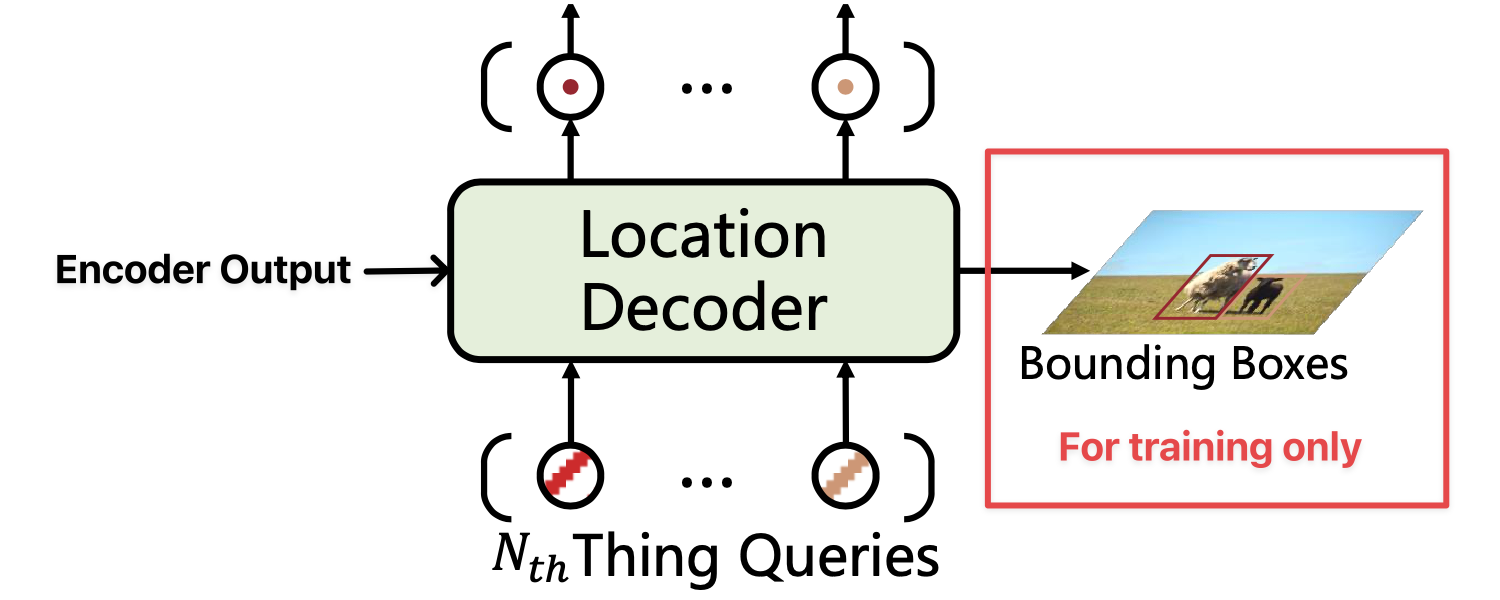
Location information is important to distinguish between difference instances. In order to include location information, the location decoder adds location information of “things” (not “stuff”) into the learnable queries used by the mask decoder.
Given randomly initialized queries and the outputs of the encoder, the location decoder will output location-aware queries using cross-attention.
During training an auxiliary MLP head is added on top of the location-aware queries to predict the bounding boxes and categories of the target object. This branch (shown in red in the diagram above) is discarded during inference.
Mask Decoder
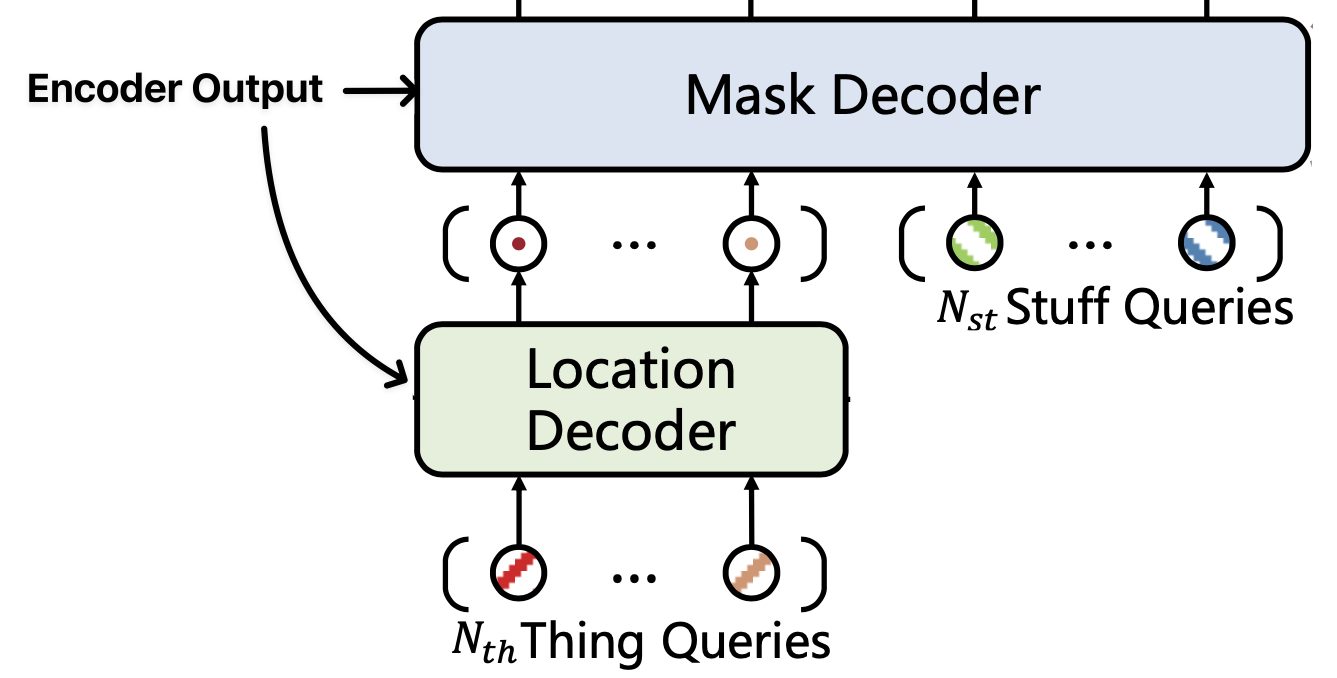
The mask decoder is for final classification and segmentation. It takes the tokens with location information from the location decoder and the randomly initialized queries. The queries don’t pass through the location decoder since there is no concept of an instance for “stuff.”
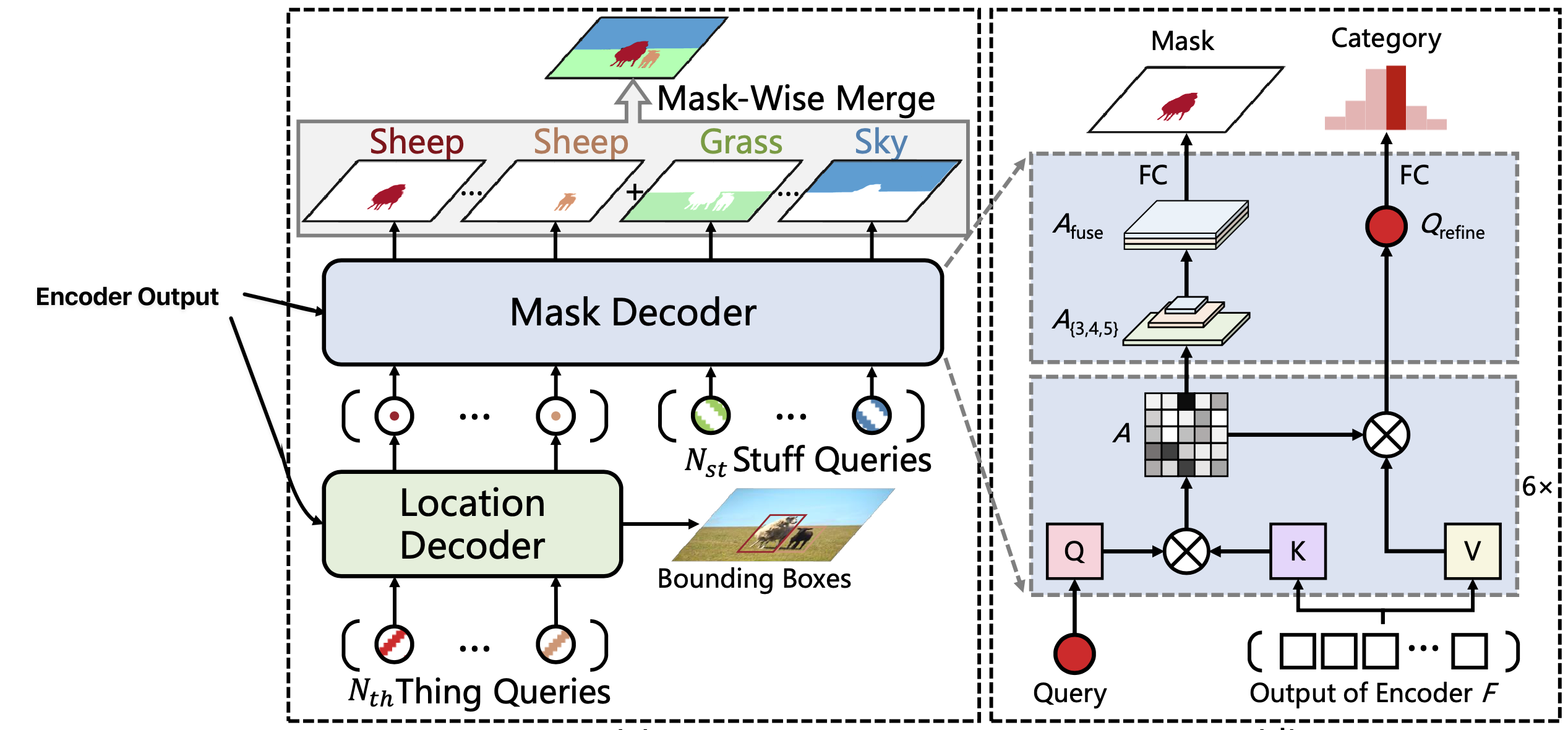
- Queries : these are the location aware thing queries and class-fixed stuff queries.
- Keys , Values : these are projected from the output of the encoder (denoted ).
- Prediction is split into category classification done via a FC layer and a binary mask prediction done via a convolution.
Category classification: Category classification is performed through a FC layer on top of the output of each decoder layer (denoted ). Each thing query needs to predict probabilities over all thing categories. Each stuff query only predicts the probability of its corresponding stuff category.
The paper uses a very lightweight FC head (only 200 parameters) to make the class predictions in the hope that this ensures the semantic information (aka class information) of the attention maps is highly related to the mask.
Binary mask prediction:
“Intuitively, the ground truth mask is exactly the meaningful region on which we expect the attention module to focus.” Therefore, the paper uses the attention maps as the input to a conv that predicts the binary mask.
Before the attention maps are passed to the conv, they are first split and reshaped into attention maps which have the same spatial dimensions as (the backbone network feature maps). This is denoted: Then, the attention maps are upsampled to the resolution which corresponds to the highest resolution backbone feature map, . The feature are then concatenated along the channel dimension once they all have the same resolution:
where and mean the 2 times and 4 times bilinear interpolation operations.
Finally, the fused attention maps are passed to a conv for binary mask prediction.
Training: During training you predict a mask and a category at each layer of the decoder. This is referred to as deep supervision and using it results in the mask decoder performing better and converging faster.
Inference: During inference only the mask and category predictions from the last layer of the decoder are used.
Mask Merging
Most papers will produce an output of where is a 0-1 distribution over the classes that can be assigned to. The papers then take a pixel-wise argmax to decide on the label for a particular pixel. The paper observed that this consistently produces false-positive results due to abnormal pixel values. Instead, they use a mask-wise merging strategy by resolving conflicts between predicted masks. They give precedence to masks with the highest confidence scores. The pseudo-code is shown below:

The mask-wise merging strategy takes , , and as input, denoting the predicted categories, confidence scores, and segmentation masks, respectively. It outputs a semantic mask SemMsk and an instance id mask IdMsk, to assign a category label and an instance id to each pixel. Specifically:
SemMskandIdMskare first initialized by zeros.- Sort prediction results in descending order of confidence score and fill the sorted predicted masks into
SemMskandIdMskin order. - Discard the results with confidence scores below and remove the overlaps with lower confidence scores. Only masks with a remaining fraction of the original mask will be kept (above ).
- Finally, the category label and unique id of each mask are added to generate non-overlap panoptic format results.
Confidence Score Calculation: The confidence score for a mask takes into account classification probability and predicted mask quality. The confidence score of the -th result is given by:
- is the most likely class probability of the -th result.
- is the mask logit at pixel .
- are hyperparameters used as exponents to balance the weight of classifcation probability and segmentation quality. Since the classification quality and predicted mask quality terms are both , having a higher exponent will result in that term’s weight being decreased.
Pixel-wise Max vs. Mask-Wise Merging
![]() When using pixel-wise argmax to decide the labels the inference results are very messy. The results are much better when using the mask-wise merging strategy.
When using pixel-wise argmax to decide the labels the inference results are very messy. The results are much better when using the mask-wise merging strategy.
Loss Functions
Overall loss ()
The overall loss for Panoptic SegFormer is: where are hyperparamters and are the losses for things and stuff.
Detection loss ()
This is the loss of Deformable DETR that is used to perform detection (bounding box loss).
Loss
Focal loss with loss weight of 2 is used for bounding box classification.
Link to original
Things loss ()
This is the overall loss function used for the thing categories:
- The values are weights to balance the three losses.
- is the number of layers in the mask decoder (the loss is calculated for all layers because of the deep supervision).
- is the classification loss implemented by Focal Loss.
- is the segmentation loss implemented by Dice Loss.
- is the focal loss for BBOX classification used by Deformable DETR.
Stuff loss ()
This is the loss for stuff. There is a one-to-one mapping between stuff queries and stuff categories and no BBOX loss is needed. Like the loss for things,
- is the classification loss implemented by Focal Loss.
- is the segmentation loss implemented by Dice Loss.
Results
- It is able to train much faster than DETR (24 epochs vs. 300+)
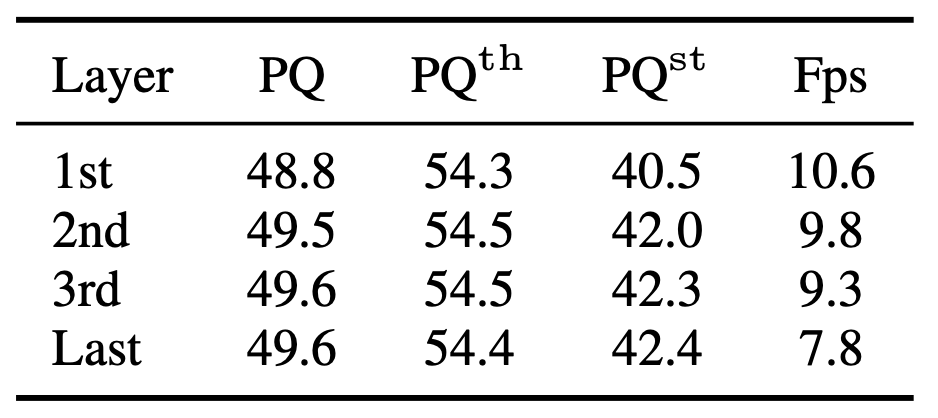 Using just the first two layers of the decoder has similar performance to using the entire mask decoder and runs much faster.
Using just the first two layers of the decoder has similar performance to using the entire mask decoder and runs much faster.
Training
- We employ a threshold 0.5 to obtain binary masks from soft masks.
- During the training phase, the predicted masks that be assigned ∅ will have a weight of zero in computing Lseg.