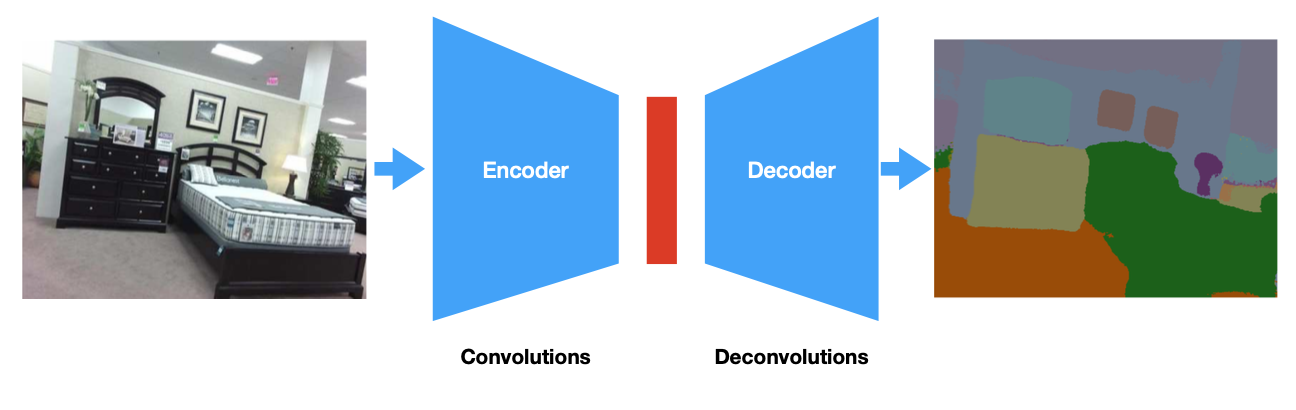
Encoder-decoder mode are used when you need a very high resolution output. You have an encoder that makes the image smaller. Then you have a second step that takes you back up in size.
U-Net Architecture: Adding Skip Connections
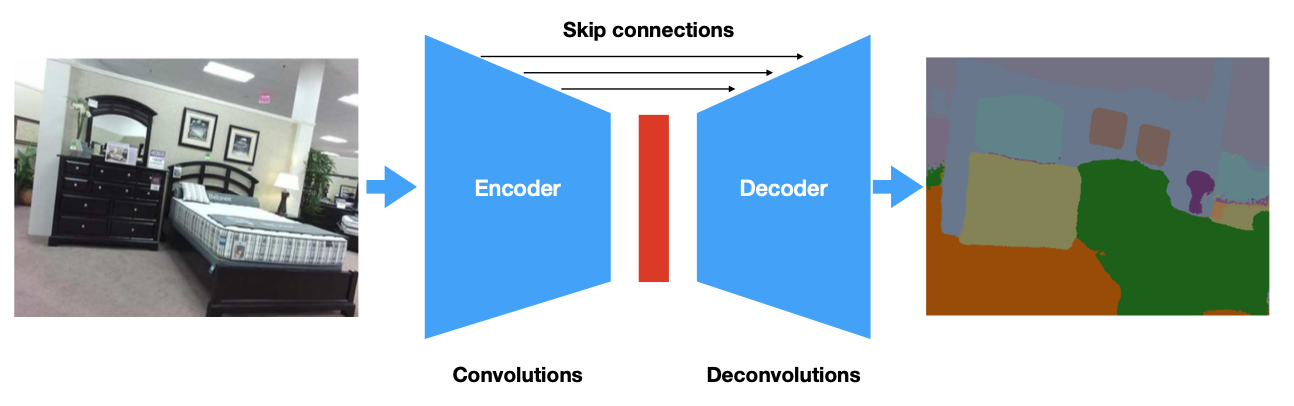
The red part of the encoder-decoder model is called the bottleneck. All the information has to pass through this, which is very restrictive. We can allow more information to flow if we add skip connections.
This will allow the later layers to access the earlier layers. This will concatenate the layers of the encoder onto the decoder layers.
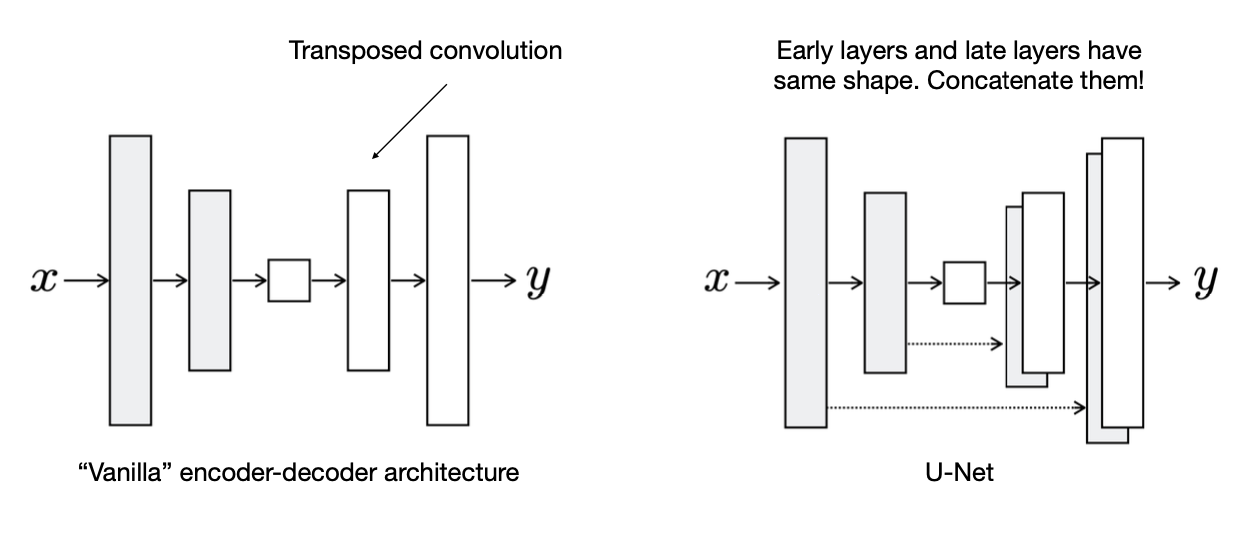
This means the last deconv layer on the far-right will receive a concatenation of both the previous layers output, as well as the left-most encoder layer’s output.
Encoder-Decoder Architecture vs. U-Net Architecture:
- U-Net is the famous Fully Convolutional Networks (FCN) in biomedical image segmentation
- U-Net is a specific implementation of an encoder-decoder network in which skip connections are used to link shallow layers with deeper ones.
- However, unlike regular encoder-decoder structures, the two parts are not decoupled for a U-Net since there are skip connections between the two parts (you can’t seperate the encoder and decoder). This means there are no real “encoder” and “decoder” parts, in the sense of mapping the sample onto some well-defined latent space and then computing the output from it. You cannot split a U-Net into parts and use them separately, as in order to compute the output, the input is needed as well - and all of its intermediate representations as well Source