The major contributions of the paper are:
- Present an efficient 3D voxel-based LiDAR multi-task network that unifies the major LiDAR perception tasks (3D semantic segmentation, object detection, and panoptic segmentation).
- Propose a novel Global Context Pooling (GCP) module to improve the global feature learning in the encoder-decoder architecture based on 3D sparse convolution by extracting global contextual features from a LiDAR frame to complement its local features.
- Introduce a second-stage refinement module to refine the first-stage semantic segmentation or produce accurate panoptic segmentation results.
The paper outperforms other approaches on the Waymo 3D semantic segmentation dataset.
Previous Work
2D segmentation and 3D indoor point cloud segmentation
Compared to 2D image and 3D indoor point cloud segmentation, outdoor LiDAR point cloud presents more challenges for the segmentation problem. Due to the large-scale and sparsity of LiDAR point clouds, well-studied 2D and indoor 3D semantic segmentation methods fail to directly adjust to LiDAR semantic segmentation.
Voxel-Based lidar segmentation
Due to the requirement of Sparse Manifold Convolutions and the need for an encoder-decoder structure for the segmentation task, previous voxel-based LiDAR segmentation networks have difficulty to learn global contextual information.
Existing approaches use Submanifold Sparse Convolution because it significantly reduces the memory and runtime of 3D CNNs by ensuring the sparsity of the network is not dilated. For encoder-decoder style networks, you can’t use Sparse Convolutions which dilate the sparsity since you need corresponding layers of the same scale to retain the same sparsity in the encoder and decoder.
Why do you need to maintain the same sparsity pattern in corresponding layers of the encoder and decoder?
- Feature Alignment: In an encoder-decoder network, the encoder extracts hierarchical features by progressively downsampling the input data. The decoder then upsamples these features to the original resolution for pixel-level predictions. To maintain feature alignment between the encoder and decoder, it is crucial to have the same sparsity pattern at each scale. If the sparsity pattern differs between the encoder and decoder, the spatial correspondence between the features will be disrupted, leading to misalignments and inconsistencies in the predictions.
- Skip Connections: Skip connections are commonly used in encoder-decoder architectures to establish direct connections between corresponding encoder and decoder layers. These connections help propagate high-resolution spatial information from the encoder to the decoder and aid in recovering fine-grained details. For the skip connections to work effectively, the sparsity pattern needs to be consistent across scales. If the sparsity pattern varies, the skip connections may introduce misalignments, negatively affecting the overall performance.
However, Submanifold Sparse Convolution can’t broadcast features to isolated voxels through multiple layers so the network is limited in learning global contextual information. This paper proposes Global Context Pooling (GCP) as the solution to extract global contextual features.
Multi-task networks
Major LiDAR perception tasks including 3D segmentation (e.g., PolarNet), 3D object detection (e.g., CenterPoint) and panoptic segmentation (e.g., Panoptic- PolarNet), are usually performed in separate and independent networks.
Global Context Pooling (GCP)
Global Context Pooling (GCP) is designed to extract global contextual feature from a 3D sparse tensor by projecting it to 2D dense BEV feature map and then converting the dense feature map back after applying 2D multi-scale feature extractor. It significantly enlarges the model’s receptive field. It can also be shared with other tasks (like object detection) by attaching additional heads with a slight increase in computational cost.
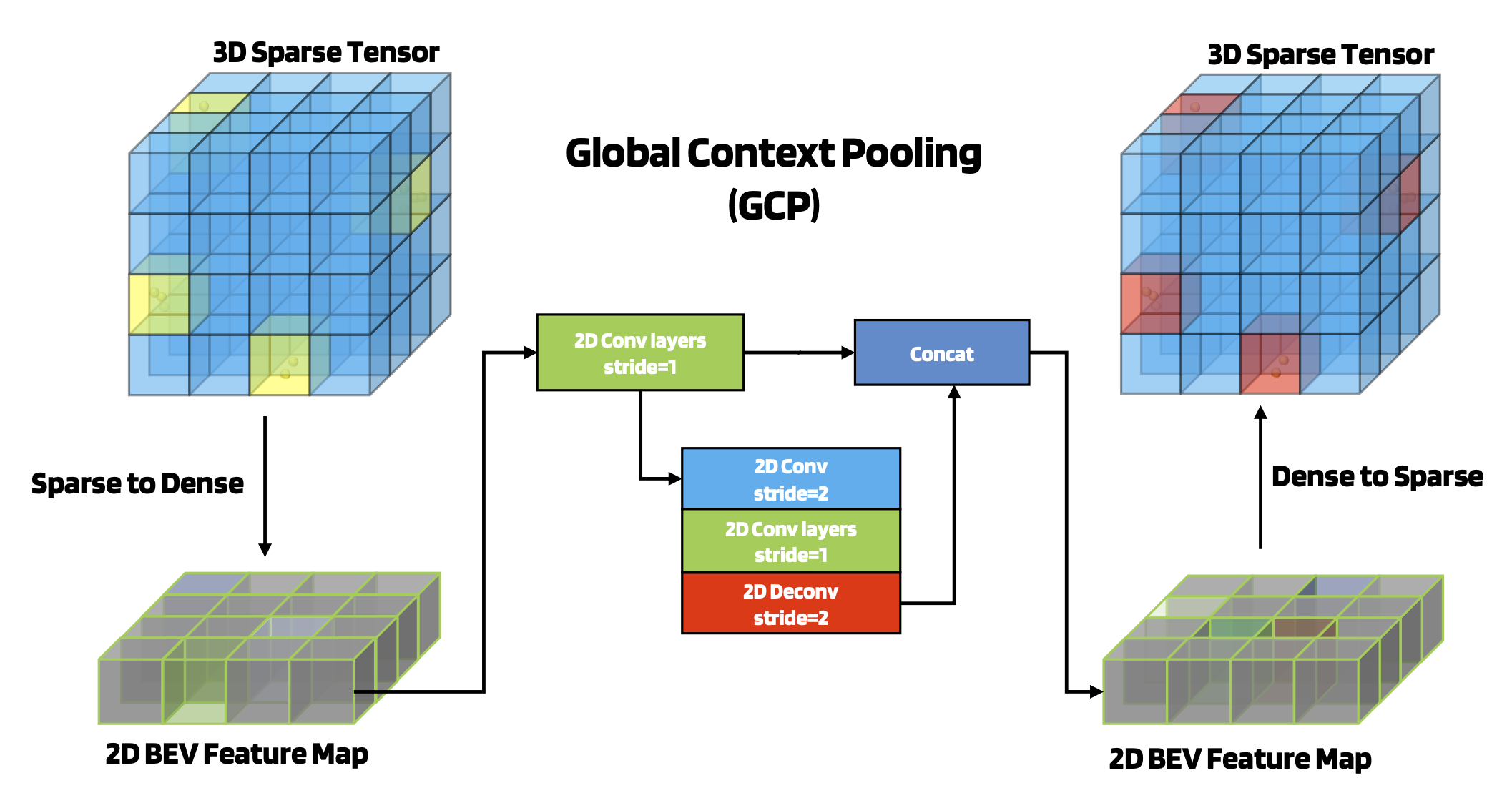
Overview: 3D sparse tensor is projected to a 2D BEV feature map. You then operate on this feature map with two 2D convolutions pathways. The two levels of 2D BEV feature maps are concatenated and then converted back to a 3D sparse tensor.
Details: The original lidar input is a set of points . You then transform the point cloud coordinates into a voxel index where is the voxel size. You then use a MLP and maxpooling layers to generate a sparse voxel feature representation .
The encoder will downsample the sparse voxel features to 1/8th the original scale. The new voxel map is denoted where is the number of valid voxels in the last scale. The GCP module will then convert this to a dense BEV feature map via where is the downsampling ratio. You then concatenate the features along the height dimension to form a 2D BEV feature map .
Then a 2D multi-scale CNN is used to extract contextual information. You then reshape the encoded BEV feature representation to the dense voxel map and transform it back to the sparse feature map following the reverse dense-to-sparse conversion.
Architecture
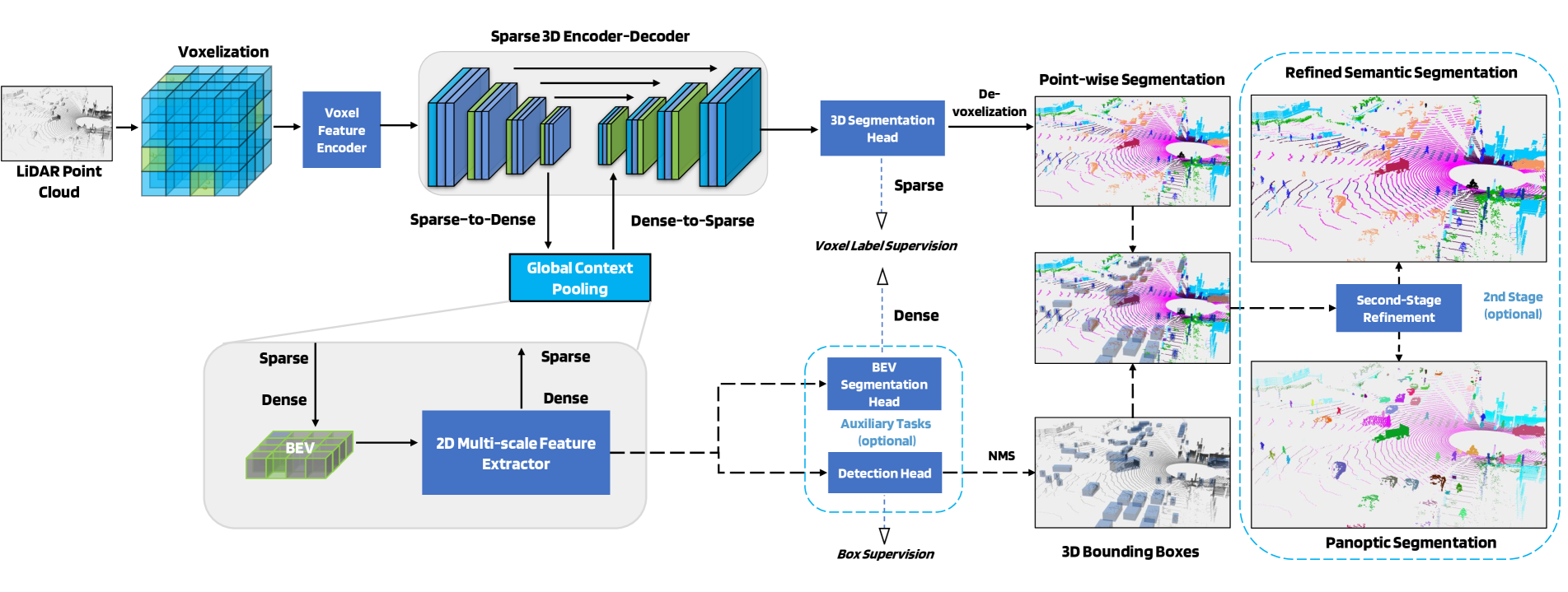
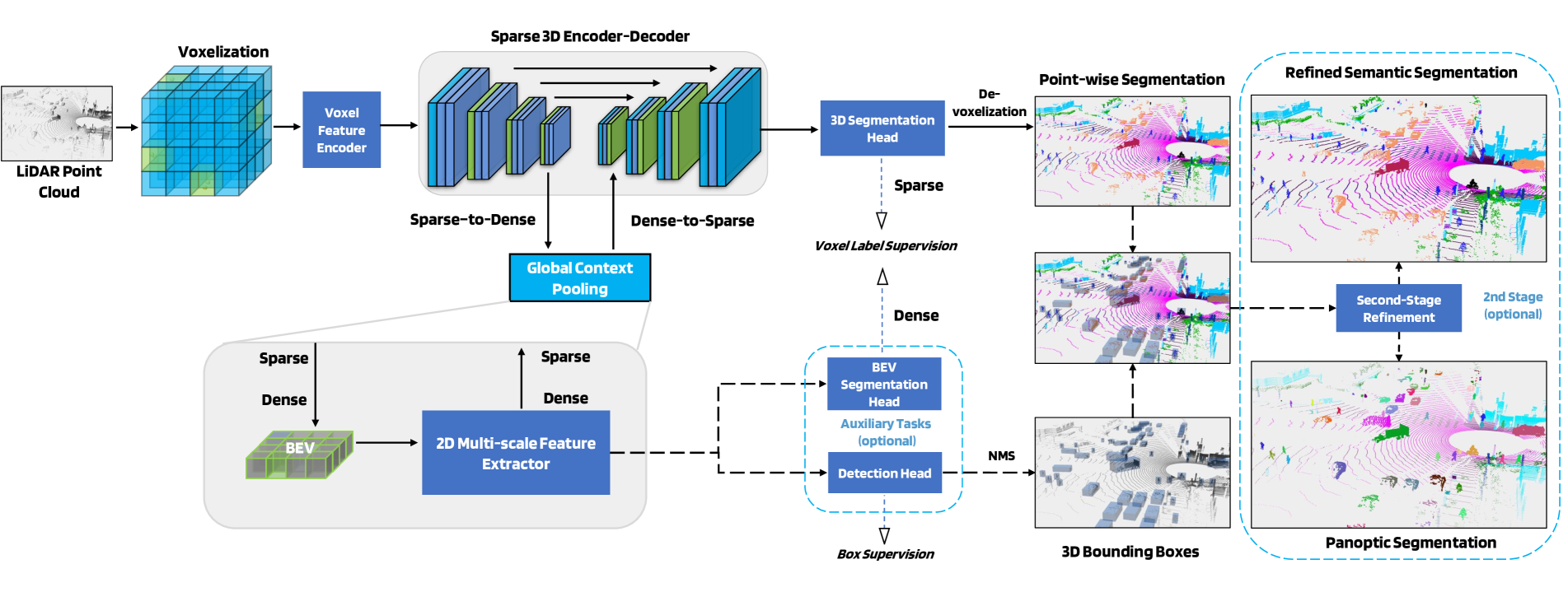 At the core of our network is a 3D encoder-decoder based on the 3D sparse convolution and deconvolutions. In between the encoder and the decoder, we apply our novel Global Context Pooling (GCP) module to extract contextual information through the conversion between sparse and dense feature maps and via a 2D multi-scale feature extractor. The 3D segmentation head is attached to the decoder output and its predicted voxel labels are projected back to the point-level via a de-voxelization step. Two auxiliary heads, namely the BEV segmentation head and 3D detection head can be attached to the 2D BEV feature map. An optional 2nd-stage produces refined semantic segmentation and panoptic segmentation results.
At the core of our network is a 3D encoder-decoder based on the 3D sparse convolution and deconvolutions. In between the encoder and the decoder, we apply our novel Global Context Pooling (GCP) module to extract contextual information through the conversion between sparse and dense feature maps and via a 2D multi-scale feature extractor. The 3D segmentation head is attached to the decoder output and its predicted voxel labels are projected back to the point-level via a de-voxelization step. Two auxiliary heads, namely the BEV segmentation head and 3D detection head can be attached to the 2D BEV feature map. An optional 2nd-stage produces refined semantic segmentation and panoptic segmentation results.
Attaching the BEV segmentation and 3D detection head to the 2D BEV feature map ensures that the Global Context Pooling is learning useful features.
Multi-Task Learning
Detection Head
They attach the detection head from CenterPoint to the 2D BEV feature map.
It predicts a class-specific centerpoint heatmap, object size and orientation, and IoU rectification score (box refinement). These are used to form initial bounding box predictions.
BEV Segmentation Head
An additional BEV segmentation head also can be attached to the 2D branch of the network, providing coarse segmentation results and serving as another auxiliary loss during training.
The head is supervised by a combination of cross entropy and Lovasz Loss.
3D Segmentation Head
The 3D segmentation head predicts voxel-level labels for the sparse 3D pixels.
Second Stage Refinement
As shown below, the points within a detection bounding box might be misclassified as multiple classes due to the lack of spatial prior knowledge.
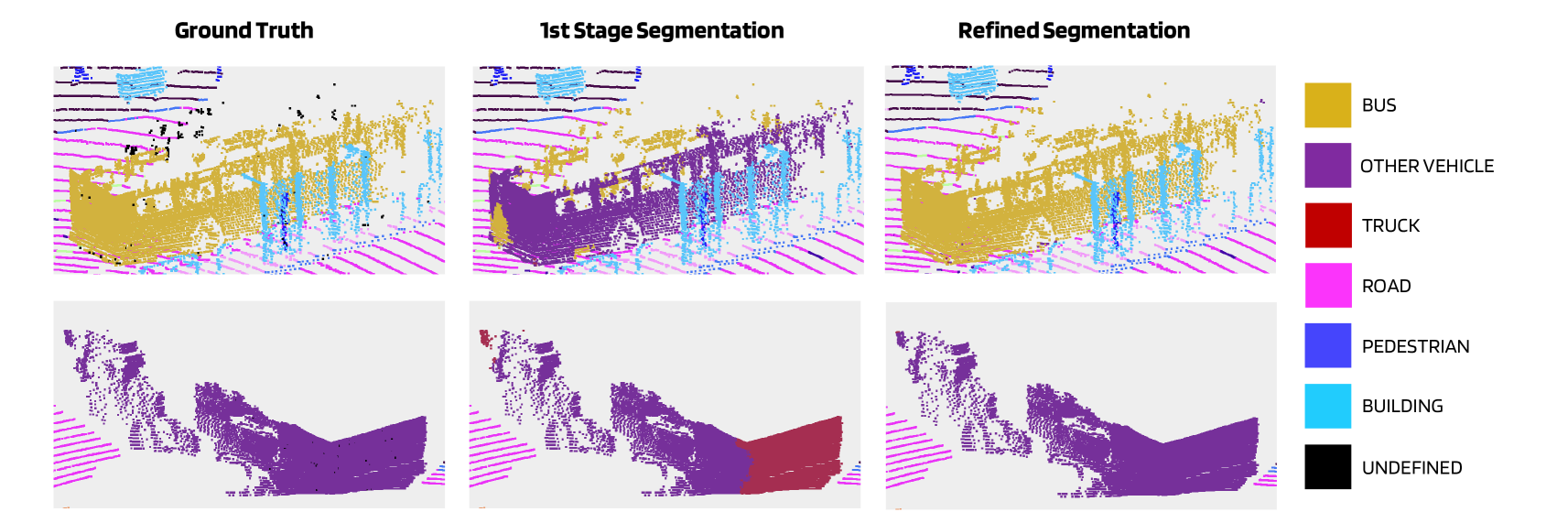 Examples of the 2nd-stage refinement. The segmentation consistency of points of the thing objects can be improved by the 2nd stage.
Examples of the 2nd-stage refinement. The segmentation consistency of points of the thing objects can be improved by the 2nd stage.
In order to improve the spatial consistency for the thing classes, they use a point-based approach as the second stage which can provide accurate panoptic segmentation results.
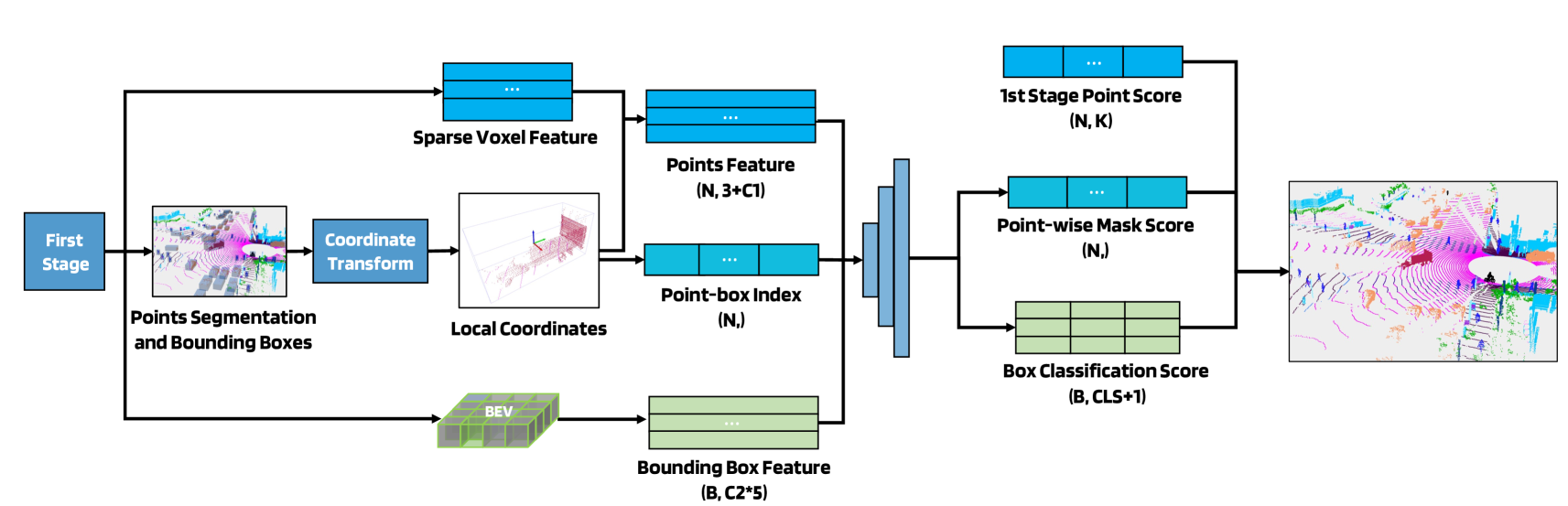
Figure 5: Illustration of the second-stage refinement pipeline. The architecture of the second-stage refinement is point-based. We first fuse the detected boxes, voxel-wise features, and BEV features from the 1st stage to generate the inputs for the 2nd stage. We apply the local coordinate transformation to the points within each box. Then, a point-based backbone with MLPs, attention modules, and aggregation modules infers the box-wise classification scores and point-wise mask scores. The final scores are computed by fusing the 1st and 2nd stage predictions.