Collapsing along height axis
The dense transformer layer is inspired by the observation that while the network needs a lot of vertical context to map features to the birds-eye-view (due to occlusion, lack of depth information, and the unknown ground topology), in the horizontal direction the relationship between BEV locations and image locations can be established using simple camera geometry. Therefore, in order to retain the maximum amount of spatial information, we collapse the vertical dimension and channel dimensions of the image feature map to a bottleneck of size , but preserve the horizontal dimension . Note: the collapsing is done via a fully-connected network (they don’t just take the max along the columns).
In the image below, you can see it is pretty straight forward to go from the BEV to the front camera column information. However, it is more difficult to decide which row a certain feature should fall into (ex. a car in the distance might be on top of a hill which would place it in a row towards the top of the image).
![]()
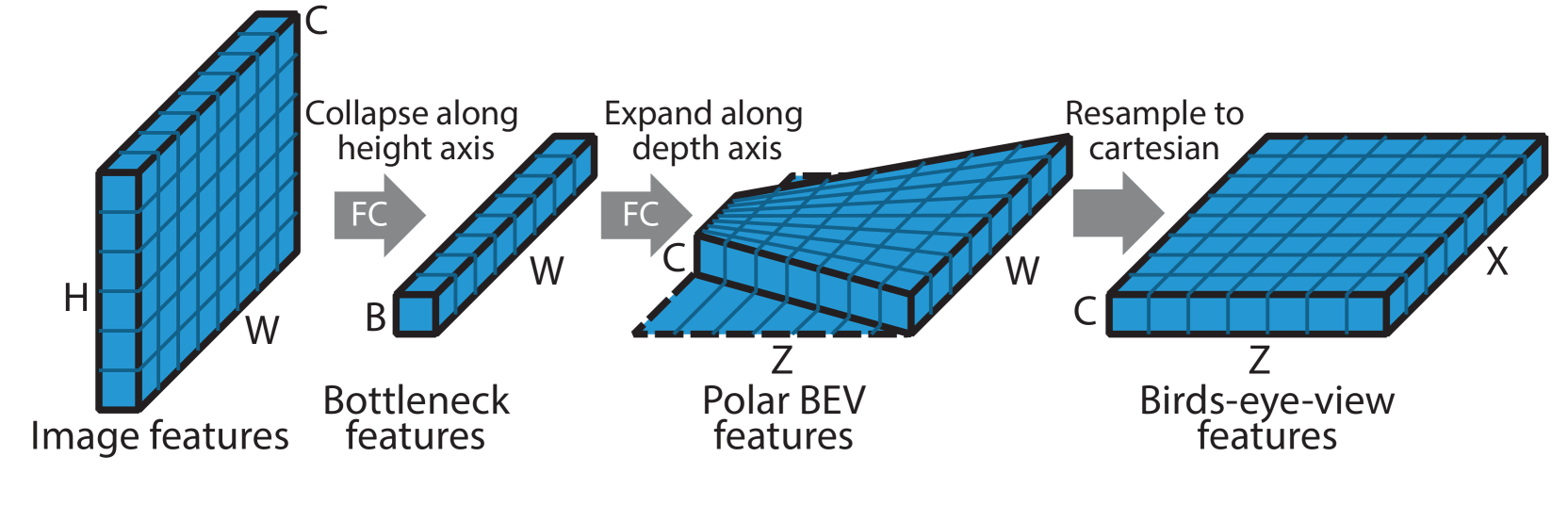 Figure 3:Our dense transformer layer first condenses the image-based features along the vertical dimension, whilst retaining the horizontal dimension.
Figure 3:Our dense transformer layer first condenses the image-based features along the vertical dimension, whilst retaining the horizontal dimension.