The original concept of prompt tuning refers to changing the prompt to the LLM to achieve better modeling results.
However, it now means adding learnable prompt tokens to pre-trained models, which are inserted either to input embeddings only or to multiple intermediate layers.
Hard Prompt Tuning
The following is an example of hard prompt tuning to achieve a better translation result:
1) "Translate the English sentence '{english_sentence}' into German: {german_translation)"
2) "English: '{english_sentence}' | German: (german_translation}"
3) "From English to German: '{english_sentence}' -> {german_translation}"
Hard prompt tuning is where you directly change the discrete input tokens which are not differentiable.
Soft Prompt Tuning
Soft prompt tuning concatenates the embeddings of the input tokens with a trainable tensor that can be optimized via backprop to improve the modeling performance on a target task. You can train a small model for a specific task that learns to generate an output that performs the model’s overall performance.
After learning a soft prompt, you have to supply it as a prefix when performing the specific task you finetuned the model on. This allows the model to tailor its responses to that particular task. Moreover, we can have multiple soft prompts, each corresponding to a different task, and provide the appropriate prefix during inference to achieve optimal results for a particular task.
Prefix Tuning
Prefix tuning is a type of prompt tuning where you add a trainable tensor to the input to each transformer block (vs. just the input embeddings as in soft prompt tuning).
What's the difference between soft prompt tuning and prefix tuning?
Soft prompt tuning concatenates the embedding of the input tokens with a tensor learned by an auxiliary model for a specific task. Prefix tuning will concatenate the additional tensor to the input of each transformer block instead of just the embedding layer.
The following figure illustrates the difference between a regular transformer block and a transformer block modified with a prefix:
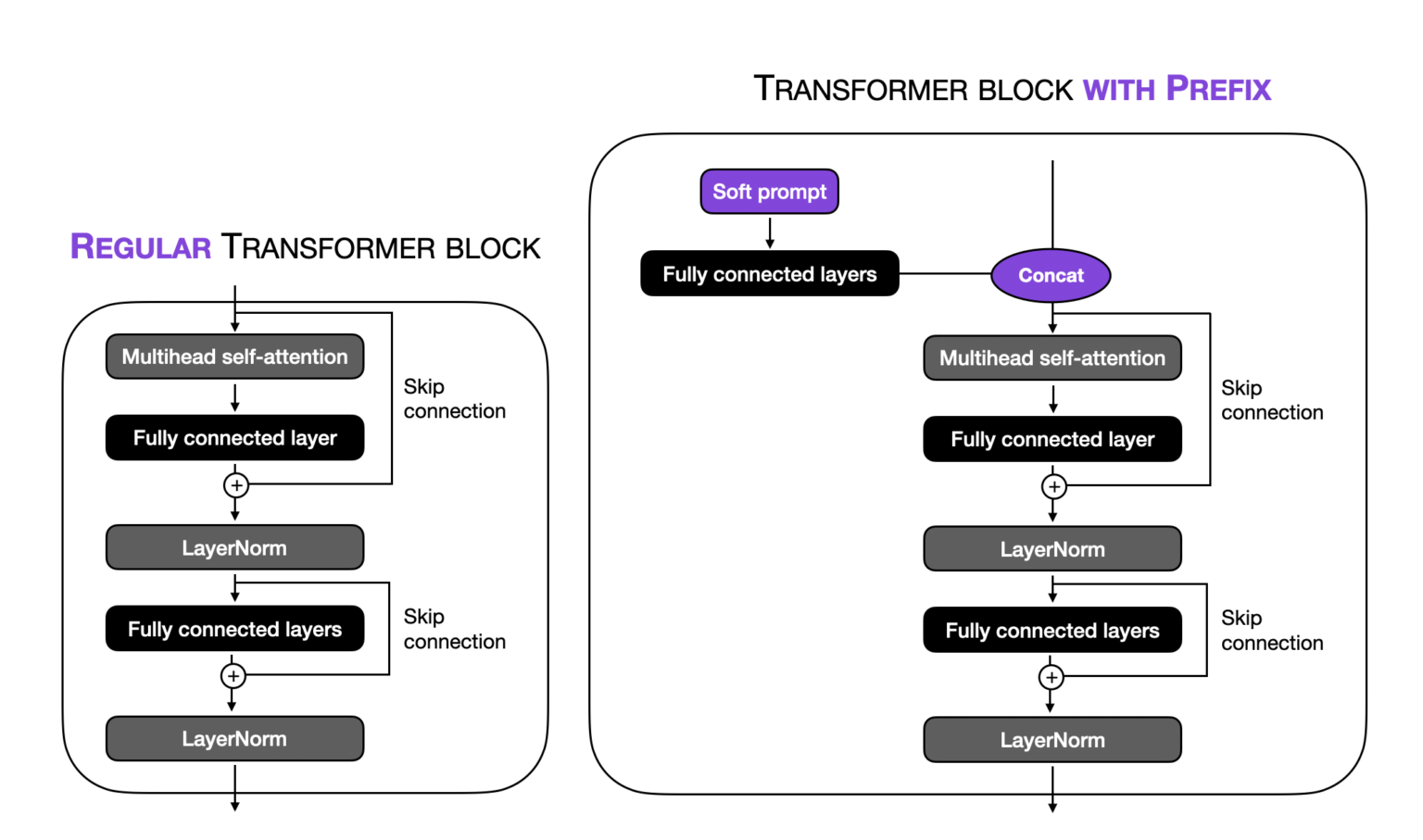
The fully connected layers embed the soft prompt in a feature space with the same dimensionality as the transformer-block input to ensure compatibility for concatenation.
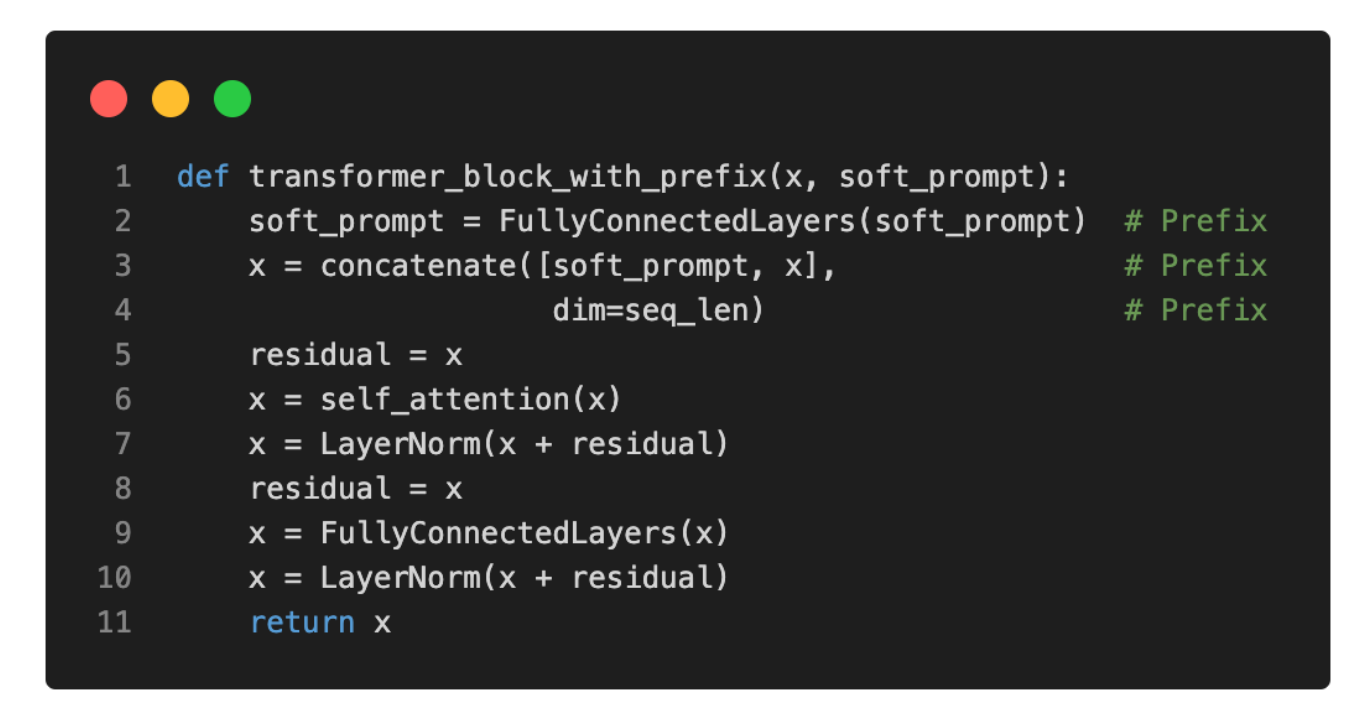
The psuedo-code is below:
Note
According to the original prefix tuning paper, prefix tuning achieves comparable modeling performance to finetuning all layers while only requiring the training of 0.1% of the parameters.
Implementation Details
The prefix is a matrix with dimensions (prefix_length x d) where is the hidden dimension size. For a prefix length of 10 and hidden size 1024, the prefix would contain 10,240 tunable parameters.
During training, the prefix values are optimized to maximize the likelihood of generating the correct output text y given input x. The gradients of the loss function are only computed with respect to the prefix parameters. The parameters of the pretrained model itself are kept completely fixed.
The authors found that directly optimizing is unstable, so they re-parameterized it with a smaller matrix which is a smaller matrix with size (prefix_length x k) where . So has fewer columns and is smaller than .
This re-parameterization with the smaller acts as a “bottleneck” that helps stabilize optimization.
Then is computed from the smaller by an MLP that expands it to the larger : . Source
After training, only the final is needed.