AI Coffee Break YouTube YouTube AI Reading Group PyTorch Code
CLIP is a vision model trained using 400 million (image, caption) pairs to learn from raw text about images (vs. using a restricted label set). This enables a deeper understanding of the images and better transferability to other datasets. During training you never force the model to narrow down an image to a single concept or word, so the model never loses or forgets other aspects of the image not captured in the class label (ex. it still knows what’s happening in the background). You can then extend the model to other tasks like image classification (you ask the model to rank the captions “This is a picture of a <dog,cat,etc.>”).
Motivation: CLIP was motivated by large scale “text-to-text” language models like GPT using web-scale collections of text vs. using labeled NLP datasets being able to zero-shot transfer to downstream datasets. They decided to try using this approach for vision models.
Main highlights of CLIP:
- Data: they train on dataset of 400 million (image, caption) pairs.
- Contrastive pre-training: they try to maximize the correct pairings of (image, caption) pairs for a batch of pairs.
- Computational efficiency: the transformer text encoder and image encoder can operate on all elements in the batch in parallel. This is computationally efficient. However, they are not necessarily data efficient since they don’t have any inductive biases (be careful with this assumption since Professor Justin Johnson thinks this is a foo foo explanation) that CNNs have that handle spatial relationships.

- Traditionally you need to have a class label per image
- Weak supervision uses many weak labels to learn image representation
- Given a dataset of images with captions, learn visual representation of images that can be transferred to downstream visual task. Use transformer based language modeling.
- This paper used contrastive learning.
- Similar to the approach used by ConVIRT
Approach
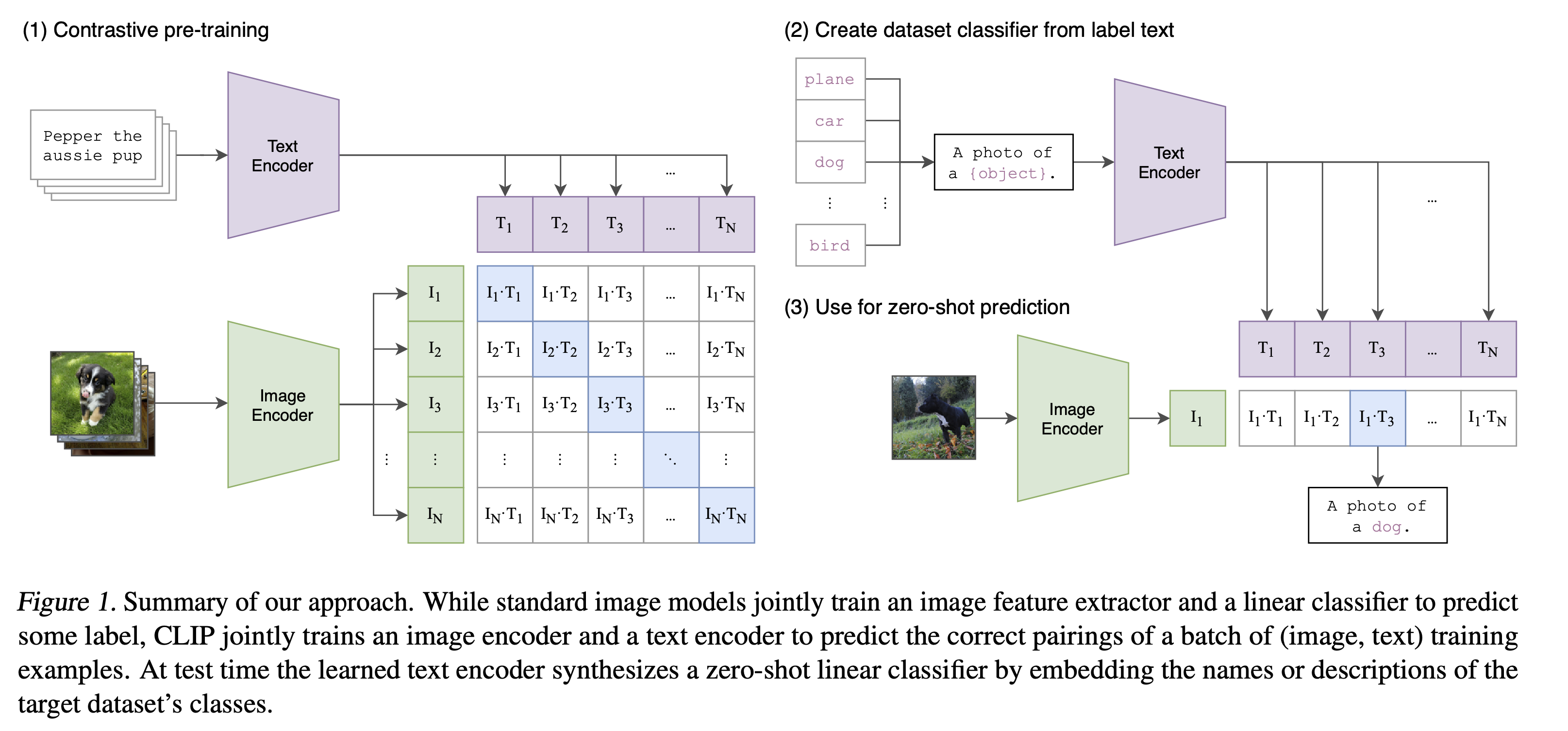
Contrastive pre-training
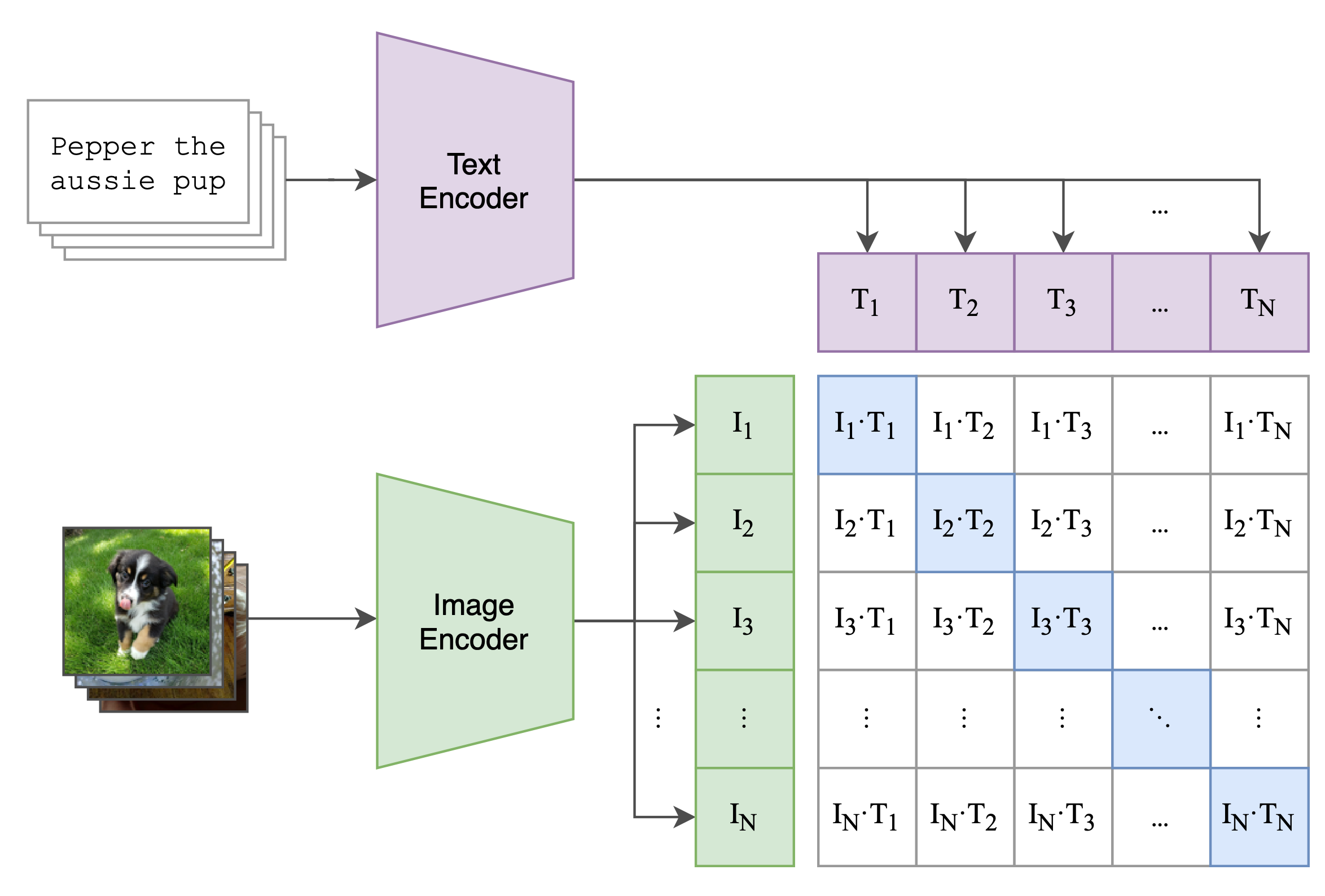
- Pass a a batch of images through an encoder. Do a linear projection on the images. This gives you images .
- Take the captions for the images, tokenize it, and pass it through a text encoder. Do a linear projection. This gives you a token embedding for each image .
- Do contrastive learning between the image embeddings and the text embeddings. You want to increase the values of the blue squares (matching image-caption pairs) to 1 and decrease the values of the white squares (non-matching image-caption pairs).
- This approach was already used as a pre-training task in the models LXMert, ViLBERT, VisualBERT.
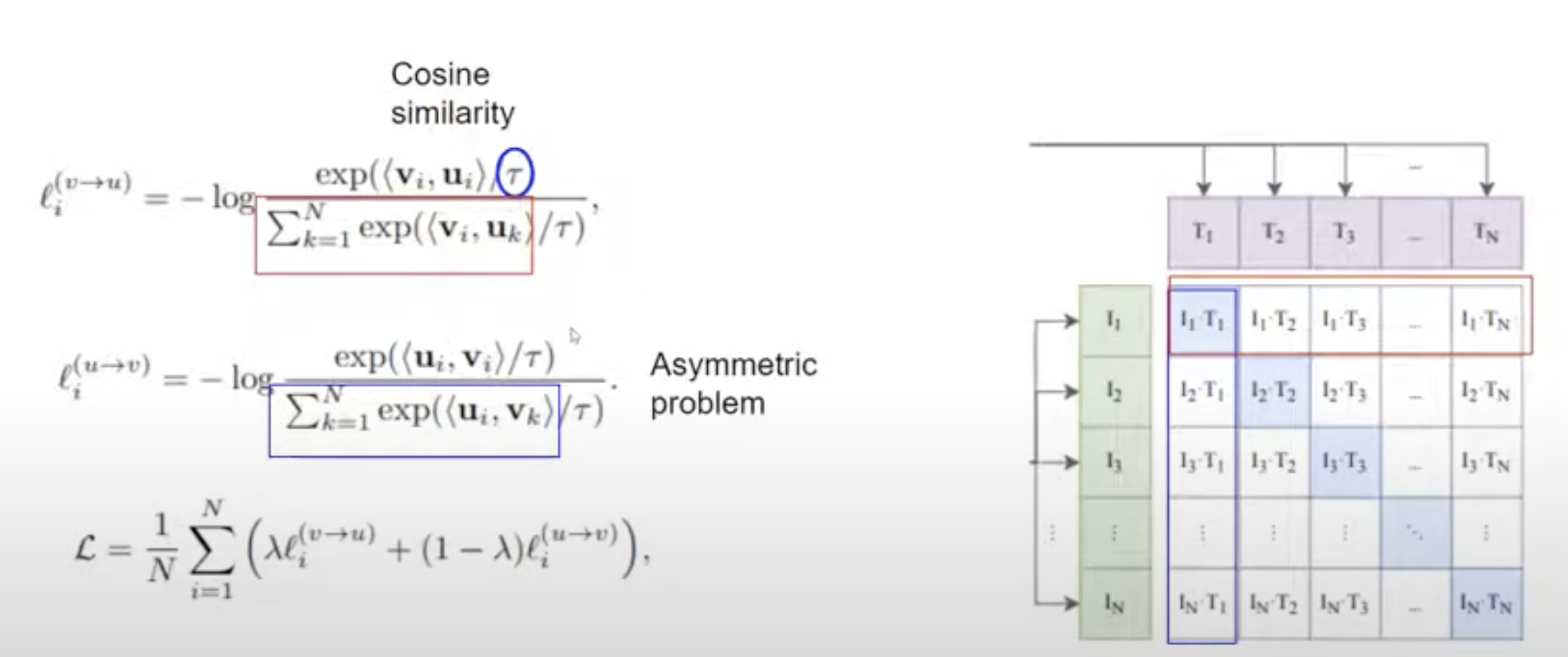
- is used to modify softmax distribution to make it more stable.
Create dataset classifier from label text
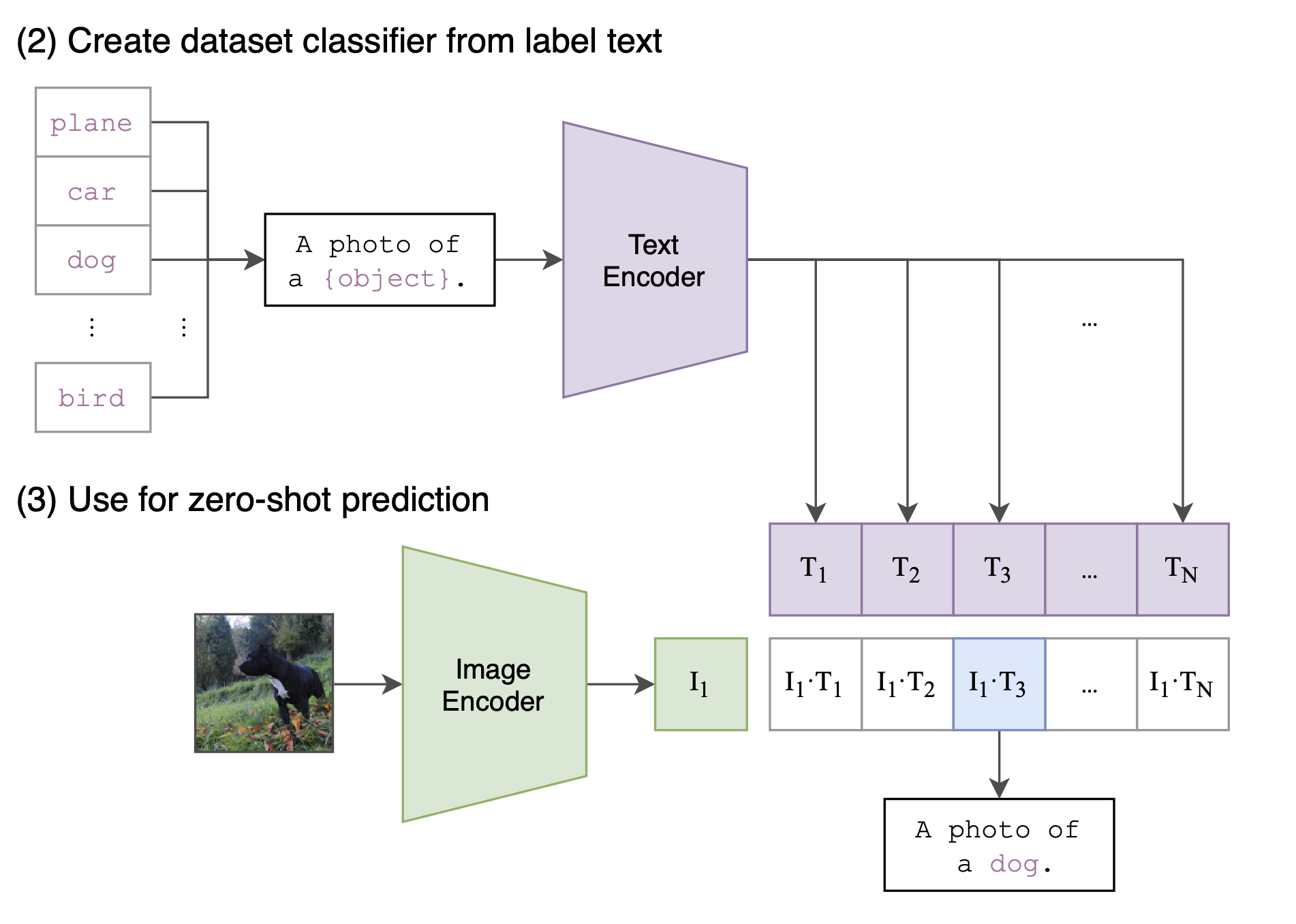
- They then try to use the trained model on CIFAR10. They take the class label for the image and then embed it into a sentence: “A photo of a {{object}}“. This sentence is then passed to the text encoder. You create text embeddings for all the labels. You restrict the classes that can be recognized by specifying what text embeddings exist (only embeddings for the labels).
- You then do zero-shot prediction. You pass it into the image encoder and then look what text embedding is closest to the predicted embedding (most similar to the image). This is then your label.
Note: you can create all the class label embeddings beforehand using the text encoder so at inference you just need to use the image encoder.
CLIP Embeddings
CLIP can take an image or text as input and map both data types to the same embedding space. This allows you to build software that can do things like: figure out which caption (text) is most fitting for an image. Source.
Limitations
Zero-shot CLIP has a similar performance with a linear classifier used on top of ResNet-50 extracted features when trained on a supervised dataset. Ex: you train a ResNet-50 with a linear classifier with 10 output labels on the CIFAR10 dataset (10 labels). A CLIP model will have similar performance without training on CIFAR10 first (only training on the 400 million image dataset).
However, its performance on zero-shot transferring is still well below the SOTA for each dataset when using the best model for that dataset. They estimate a 1000x increase in compute is needed for zero-shot CLIP to reach SOTA performance.
CLIP also struggled with fine-grained classification like differentiating models of cars, species of flowers, and variants of aircraft. CLIP also struggles with more abstract tasks like counting the number of objects in an image. It can have near random performance on novel tasks like classifying the distance between objects in a photo.
It also does not work well for images out of the data distribution it was trained on. It does very well on digitally rendered text OCR but performs quite poorly on MNIST (simple handwritten digits). This is because there were no similar images to MNIST in its dataset (no handwritten text).
Additionally, CLIP can’t generate captions. It can only tell you how well a caption and an image fit together.
CLIP also does not address the poor data efficiency of deep learning. Instead CLIP compensates by using a source of supervision that can be scaled to hundreds of millions of training examples.