CenterPoint is a two-stage 3D detector that finds centers of objects and their properties using a keypoint detector and regresses to other attributes, including 3D size, 3D orientation and velocity. In a second-stage, it refines these estimates using additional point features on the object.
CenterPoint uses a lidar-based backbone network (ex. VoxelNet or PointPillars) to build a representation of the input point-cloud. It then flattens this representation into an overhead map-view and uses a standard image-based keypoint detector (Objects as Points) to predict a heatmap with the likelihood of object centers. The peaks of the heatmap correspond to object centerpoints. For each detected center, it regresses to all other properties such as 3D size, orientation, and velocity from a point-feature at the center location (it uses the features from the feature grid that correspond to the object’s centerpoint).
Center Heatmap Head
The center-head’s goal is to produce a heatmap peak at the center location of any detected object. This head produces a -channel heatmap , one channel for each of classes (the heatmaps are independent of class). During training, it targets a 2D Gaussian produced by the projection of 3D centers of annotated bounding boxes into the map-view.
Increasing positive supervision
In the above example you can see how objects in a top down map view are sparser than in an image. In map-view, distances are absolute, while an image-view distorts them by perspective. Consider a road scene, in map-view the area occupied by vehicles small, but in image-view, a few large objects may occupy most of the screen.
Using the standard supervision of CenterNet results in a very sparse supervisory signal where most of the locations are considered background. To counteract this, they increase the positive supervision for the target heatmap by enlarging the Gaussian peak rendered at each ground truth object center. This allows the model to get more signal from pixels close to the object center.
Regression Heads
They use multiple independent regression (predicts a continuous value) heads: a sub-voxel location refinement , height-above-ground , the 3D size of the box , and a yaw rotation angle . These values provide the full information needed to get a 3D bounding box.
Sub-voxel refinement This helps reduce quantization error from voxelization and striding of the backbone network.
Height above ground This helps localize the object in 3D and adds missing elevation information removed by the map-view projection.
Two-Stage CenterPoint
The second stage of CenterPoint predicts a class-agnostic box confidence score and a box refinement.
The second stage of CenterPoint extracts additional point-features from the 2D flattened output of the backbone. They extract point features from each face of the predicted bounding box. However, in the top-down view the center of the top face, center of the bottom face, and center of the BBOX all project to the same 2D point (shown as the blue circles in the box on the left). Therefore, they only use the centers of the four outward-facing box-faces + the predicted object center point (marked as ‘x’s on the right).
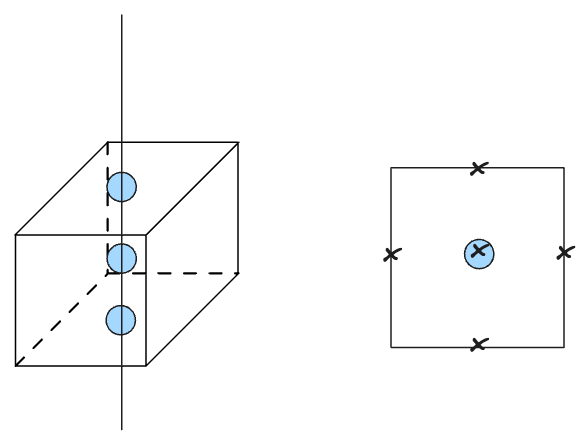
For each point they extract a feature using bilinear interpolation from the backbone map-view output . They then concatenate the extracted point-features and pass them through an MLP. The second stage then predicts a class-agnostic confidence score and box refinement.
Box Refinement (aka IoU Rectification)
In the context of CenterPoint, IoU rectification refers to a technique used to improve the accuracy of 3D object detection by refining the predicted bounding boxes.
IoU, or Intersection over Union, is a commonly used evaluation metric in object detection tasks. It measures the overlap between the predicted bounding box and the ground truth bounding box of an object. A higher IoU indicates a better alignment between the predicted and ground truth boxes.
In IoU rectification, after the initial detection process, the predicted bounding boxes are adjusted or rectified to maximize their IoU with the ground truth boxes. This rectification step helps refine the localization accuracy of the detected objects.